 |
VOOZH | about |
|
VOOZH | about |
Information Gain and Mutual Information are used to measure how much knowledge one variable provides about another. They help optimize feature selection, split decision boundaries and improve model accuracy by reducing uncertainty in predictions.
Some common reasons why these measures are essential are:
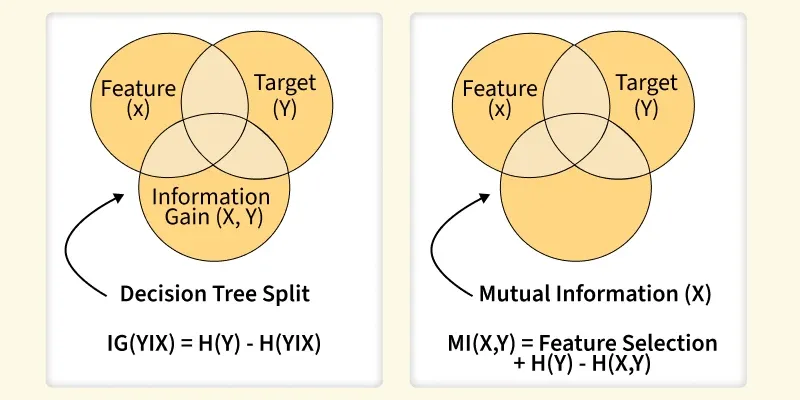
Information Gain quantifies the reduction in entropy after splitting the data on a particular feature. Higher gain means a more useful split.
Where:
Calculating information gain using iris dataset.
Output:
Information Gain for each feature: [0.50576572 0.27875048 0.98425371 0.99358193]
Petal length and petal width are highly informative features compared to sepal length and sepal width for predicting the species of Iris flowers.
Mutual Information measures how strongly two variables depend on each other. It works well for both linear and non-linear relationships.
Where:
Implementing Mutual Information using mutual_info_regression and generating data synthetically.
Output:
Mutual Information for each feature: [0.42283584 0.54090791]
Higher Mutual Information values suggest a stronger relationship or dependency between the features and the target variable.
Information Gain Ratio normalizes Information Gain to reduce bias toward attributes with many values.
Where:
Calculating IGR.
Output:
IGR: 0.11232501392736335
An IGR of 0.1123 is considered low, the feature is not very informative for splitting the data compared to other possible features.
Difference between information gain and mutual information:
Criteria | Information Gain (IG) | Mutual Information (MI) |
|---|---|---|
Definition | Measures reduction in uncertainty of the target variable when a feature is known. | Measures how much knowing one variable reduces uncertainty about another. |
Focus | Individual feature importance | Mutual dependence and information exchange between variables |
Usage | Commonly used in decision trees for feature selection | Versatile application in feature selection, clustering and dimensionality reduction |
Interactions | Ignores feature interactions | Considers interactions between variables, capturing complex relationships |
Applicability | Effective for discrete features with clear categories | Suitable for both continuous and discrete variables, capturing linear and nonlinear relationships |
Computation | Simple to compute | Can be computationally intensive for large datasets or high-dimensional data |
{kind=link}
{kind=link}