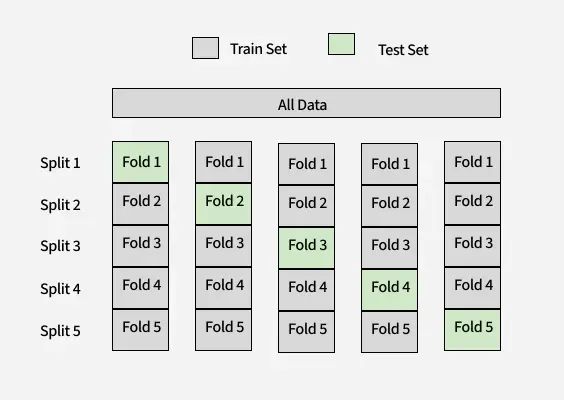
K-Fold Cross Validation is a statistical technique to measure the performance of a machine learning model by dividing the dataset into K subsets of equal size (folds). The model is trained on K − 1 folds and tested on the last fold. This process is repeated K times, with each fold being used as the testing set exactly once. The performance of the model is then averaged over all K iterations to provide a robust estimate of its generalization ability.
Avoids Overfitting: Ensures that the model does not perform well only on the training data but generalizes to unseen data.
Provides Robust Evaluation: Averages results over multiple iterations, reducing bias and variance in the performance metrics.
Efficient Use of Data: Maximizes the utilization of the dataset, especially when the data size is limited.
K-Fold Cross Validation
The process can be broken into the following steps:
1. Split Data into K Folds: Divide the dataset into K subsets or folds.
2. Train-Test Iterations: For each fold:
Use K −1 folds for training the model.
Use the remaining fold as the test set to evaluate the model.
3. Aggregate Results: Calculate the performance metric (e.g., accuracy, precision, recall, etc.) for each fold and average the results.
Let 𝐷 be the dataset, split into 𝐾 folds. For each fold 𝑘, the training set is:
and the test set is:
The model's performance is computed as:
Choosing the Value of K
The choice of K affects the trade-off between bias and variance:
Small K (e.g., K =2 or K=5): Faster computation with increased variance in performance estimates.
Large K (e.g., K =10 or K =n, where n is the size of the dataset): Lower variance but higher computational cost. K =n corresponds to Leave-One-Out Cross Validation (LOOCV).
A standard choice is 10-Fold Cross Validation that is a good trade-off between bias and variance in most situations.
Variants of K-Fold Cross Validation
Stratified K-Fold Cross Validation: Maintains the same class distribution for each fold as for the entire dataset, particularly helpful for datasets that are imbalanced.
Repeated K-Fold Cross Validation: Performs the K-Fold operation several times with varying splits, giving more stable performance estimates.
Here’s a Python example of how to implement K-Fold Cross Validation using the scikit-learn library:
Output:
Accuracy for each fold: [0.96666667 0.96666667 0.93333333 0.96666667] Average Accuracy: 0.97
Explanation: This code does K-Fold Cross Validation with a RandomForestClassifier on the Iris dataset. It divides the data into 5 folds, trains the model on each fold and checks its accuracy. The accuracy of each fold is printed, as well as the average accuracy over all folds.
Benefits of K-Fold Cross Validation
Efficient Data Usage: Every data point is used for both training and testing.
Reliable Estimates: Reduces the likelihood of overfitting or underfitting.
Applicability: Works well with small datasets or when data collection is expensive.
Time-Series Data: For time-series data, where the order of observations is crucial, a modification called Time Series Cross Validation is used. The training set consists of all data points up to time t, and the test set includes all data points at time t+1 and beyond.
Limitations of K-Fold Cross Validation
Computational Cost: Re-training the model k times can be time-consuming, especially for large datasets or complex models.
Data Leakage Risk: Care must be taken to ensure that no data preprocessing (e.g., scaling, encoding) leaks information from the test set into the training set.
Not Ideal for Time-Series Data: Sequential dependencies in time-series data may render K-Fold inappropriate without modifications like time-based splits.

{kind=link}
{kind=link}