Anomaly Detection is the technique of identifying rare events or observations which can raise suspicions by being statistically different from the rest of the observations. Such "anomalous" behaviour typically translates to some kind of a problem like a credit card fraud, failing machine in a server, a cyber attack, etc.
An anomaly can be broadly categorized into three categories -
- Point Anomaly: A tuple in a dataset is said to be a Point Anomaly if it is far off from the rest of the data.
- Contextual Anomaly: An observation is a Contextual Anomaly if it is an anomaly because of the context of the observation.
- Collective Anomaly: A set of data instances help in finding an anomaly.
Anomaly detection can be done using the concepts of Machine Learning. It can be done in the following ways -
- Supervised Anomaly Detection: This method requires a labeled dataset containing both normal and anomalous samples to construct a predictive model to classify future data points. The most commonly used algorithms for this purpose are supervised Neural Networks, Support Vector Machine learning, K-Nearest Neighbors Classifier, etc.
- Unsupervised Anomaly Detection: This method does require any training data and instead assumes two things about the data ie Only a small percentage of data is anomalous and Any anomaly is statistically different from the normal samples. Based on the above assumptions, the data is then clustered using a similarity measure and the data points which are far off from the cluster are considered to be anomalies.
We now demonstrate the process of anomaly detection on a synthetic dataset using the K-Nearest Neighbors algorithm which is included in the pyod module.
Step 1: Importing the required libraries
Step 2: Creating the synthetic data
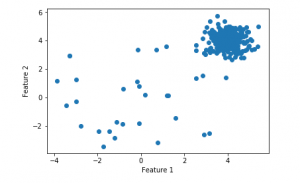
Step 3: Visualising the data
👁 Image
Step 4: Training and evaluating the model
👁 Image
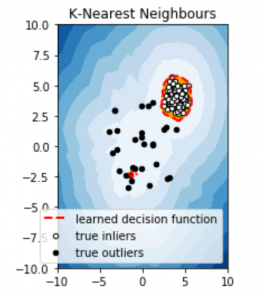
Step 5: Visualising the predictions
👁 Image

{kind=link}
{kind=link}
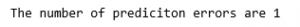{kind=link}
{kind=link}