Mask R-CNN is an advanced computer vision model used for object detection and instance segmentation. It extends Faster R-CNN by adding a mask prediction branch that generates pixel-level segmentation masks for detected objects.
Detects objects and predicts bounding boxes
Generates segmentation masks for each object instance
Uses a Fully Convolutional Network (FCN) for mask prediction
Provides accurate pixel-level object segmentation
Widely used in computer vision and image analysis applications
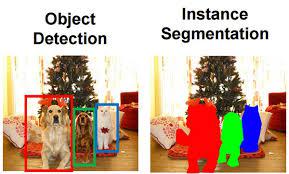
Instance Segmentation
Instance segmentation identifies and separates each individual object present in an image by assigning unique pixel-level masks to every object instance.
Detects and segments each object separately
Classifies individual pixels belonging to objects
Generates segmentation masks for each object instance
Provides detailed object boundaries and localisation
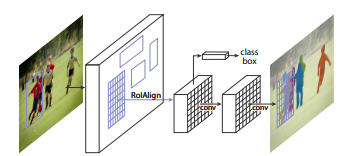
Mask R-CNN extends the two-stage Faster R-CNN architecture by adding a separate mask prediction branch for instance segmentation. It detects objects, classifies them and generates pixel-level segmentation masks for each object instance.
Performs object classification and bounding box prediction
Adds a parallel mask branch for segmentation mask generation
Uses RoI Align for accurate pixel-to-pixel feature alignment
Produces class labels, bounding boxes and segmentation masks as output
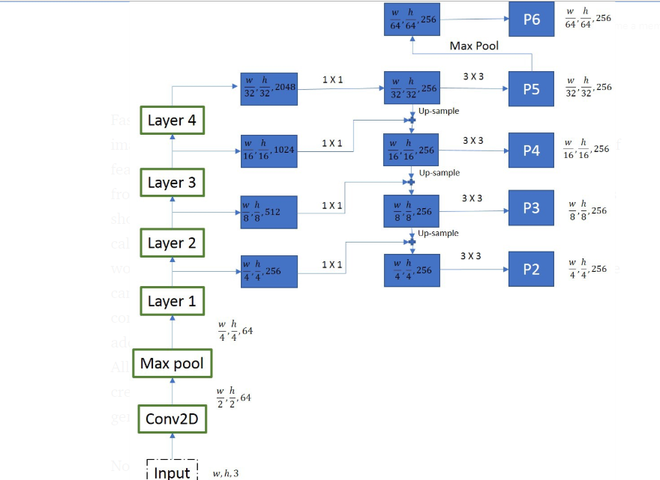
Mask R-CNN Architecture
Mask R-CNN was proposed by Kaiming He et al. in 2017 as an extension of Faster R-CNN for instance segmentation. Along with object detection and bounding box prediction, it also generates a binary segmentation mask for each detected object.
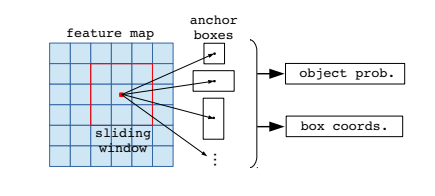
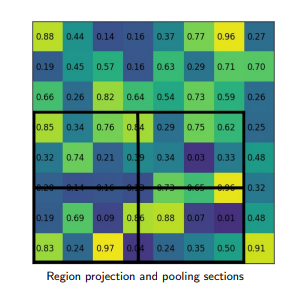
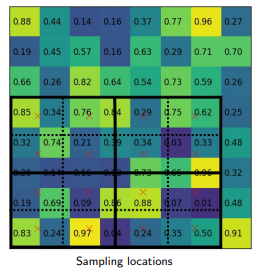
Given the feature map of the previous Convolution layer of size h*w, divide this feature map into M * N grids of equal size (we will NOT just take integer value).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}