 |
VOOZH | about |
|
VOOZH | about |
Traditional Convolutional Neural Networks (CNNs) with fully connected layers often struggle with object detection tasks, especially when dealing with multiple objects of varying sizes and positions within an image. A brute-force method like applying a sliding window across the image to detect objects is highly computationally expensive, as it fails to scale efficiently when object frequency and variation increase.
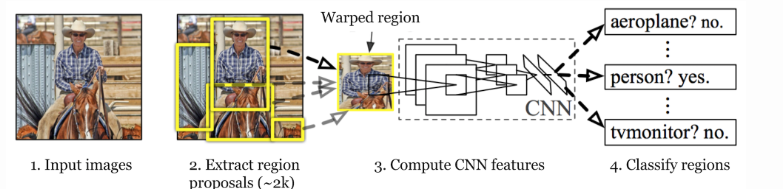
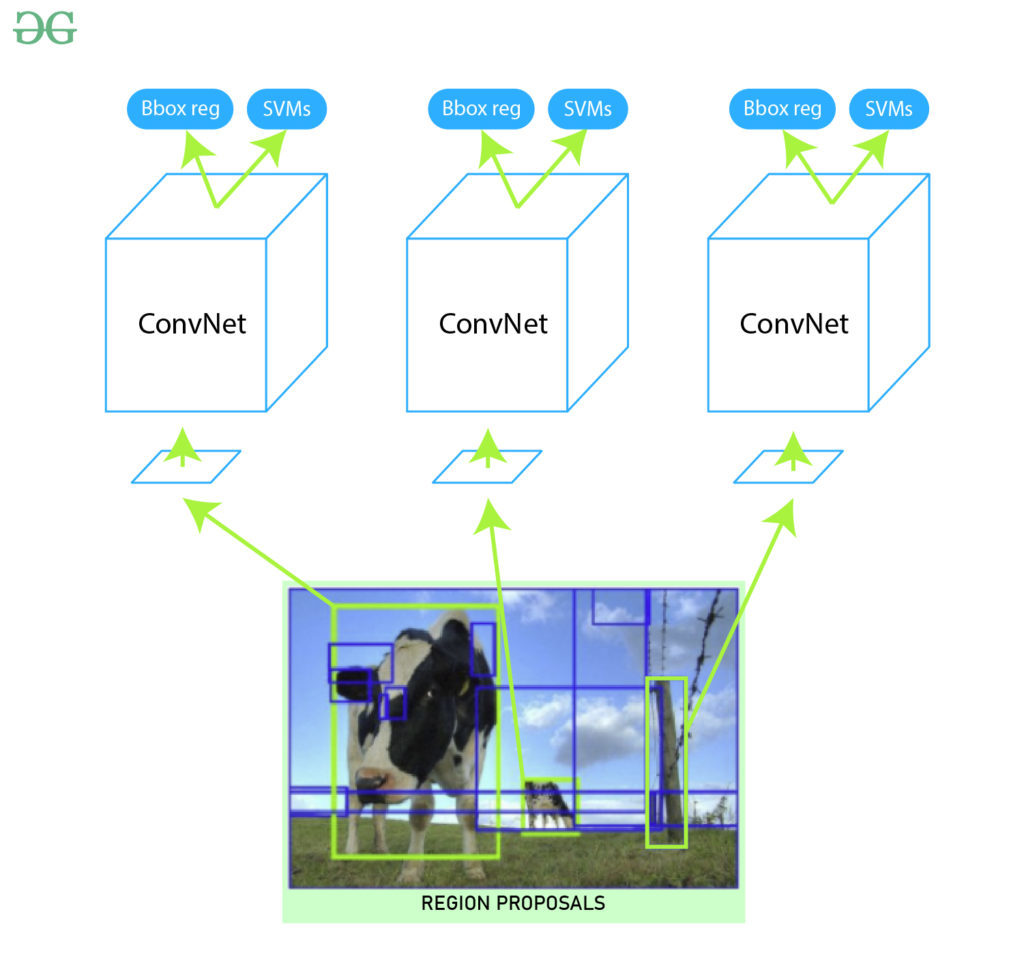
To overcome these challenges, R-CNN (Regions with CNN features) was introduced. R-CNN presents a smarter approach by using a selective search algorithm to generate around 2,000 region proposals from an image. These proposals are likely to contain objects and are individually processed to detect and localize them more efficiently. R-CNN marked a significant advancement in the field of object detection and laid the foundation for faster and more accurate object detection models.
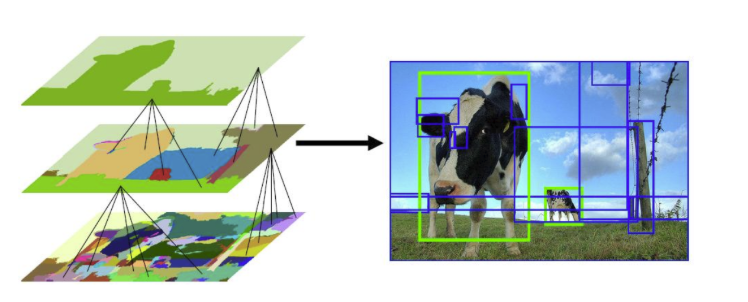
R-CNNs begin by generating region proposals, which are smaller sections of the image that may contain the objects we are searching for. The algorithm employs a method called selective search, a greedy approach that generates approximately 2,000 region proposals per image. Selective search effectively balances the number of proposals while maintaining high object recall, ensuring efficient object detection.
By limiting the number of regions for detailed analysis, this method enhances the overall performance of the R-CNN in detecting objects within images.
Selective Search is a greedy algorithm that generates region proposals by combining smaller segmented regions. It takes an image as input and produces region proposals that are crucial for object detection. This method offers significant advantages over random proposal generation by limiting the number of proposals to approximately 2,000 while ensuring high object recall.
Algorithm Steps:
The selective search algorithm provides an efficient way to identify potential object regions, enhancing the overall effectiveness of the detection process.
For a more detailed exploration of the selective search algorithm, please refer to the full discussion in this article.
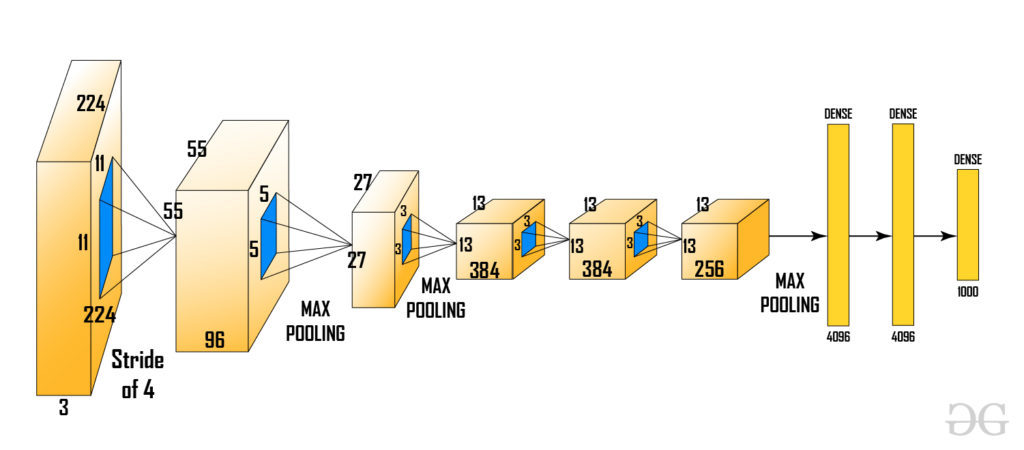
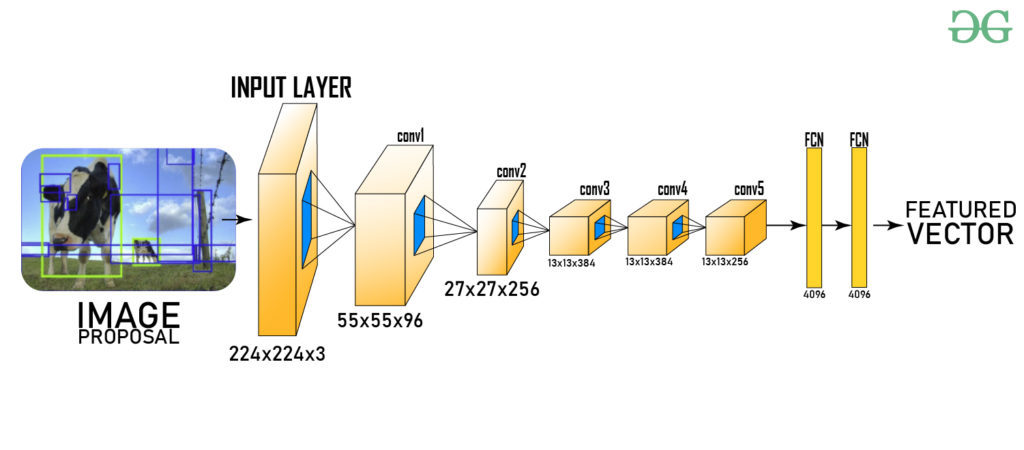
After generating the region proposals, these regions are warped into a uniform square shape to match the input dimensions required by the CNN model. In this case, we use the pre-trained AlexNet model, which was considered the state-of-the-art CNN for image classification at the time.
The input size for AlexNet is (227, 227, 3), meaning each input image must be resized to these dimensions. Consequently, whether the region proposals are small or large, they need to be adjusted accordingly to fit the specified input size.
From the above architecture, we remove the final softmax layer to obtain a (1, 4096) feature vector. This feature vector is then fed into both the Support Vector Machine (SVM) for classification and the bounding box regressor for improved localization.
The feature vector generated by the CNN is then utilized by a binary Support Vector Machine (SVM), which is trained independently for each class. This SVM model takes the feature vector produced by the previous CNN architecture and outputs a confidence score indicating the likelihood of an object being present in that region.
However, a challenge arises during the training process with the SVM: it requires the AlexNet feature vectors for each class. As a result, we cannot train AlexNet and the SVM independently and in parallel.
To accurately locate the bounding box within the image, we utilize a scale-invariant linear regression model known as the bounding box regressor. For training this model, we use pairs of predicted and ground truth values for four dimensions of localization: . Here, and represent the pixel coordinates of the center of the bounding box, while and indicate the width and height of the bounding boxes, respectively.
This method enhances the Mean Average Precision (mAP) of the results by 3-4%.
👁 ImageTo further optimize detection, R-CNNs apply Non-Maximum Suppression (NMS):
By combining region proposals, selective search, CNN-based feature extraction, SVM classification, and bounding box refinement, R-CNN achieves high accuracy in object detection, making it suitable for various applications.
After that, we can obtain output by plotting these bounding boxes on the input image and labeling objects that are present in bounding boxes.
The R-CNN gives a Mean Average Precision (mAPs) of 53.7% on VOC 2010 dataset. On 200-class ILSVRC 2013 object detection dataset it gives an mAP of 31.4% which is a large improvement from the previous best of 24.3%. However, this architecture is very slow to train and takes ~ 49 sec to generate test results on a single image of the VOC 2007 dataset.
Following the introduction of R-CNN, several variations emerged to address its limitations:
Fast R-CNN optimizes the R-CNN architecture by sharing computations across proposals. Key improvements include:
Faster R-CNN further advances the R-CNN framework by incorporating a Region Proposal Network (RPN). Key features include:
Building upon Faster R-CNN, Mask R-CNN was introduced to extend the model to perform instance segmentation. Key features include:
Cascade R-CNN implements a multi-stage object detection framework to improve detection performance. Key aspects include:
R-CNN faces several challenges in its implementation:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}