 |
VOOZH | about |
|
VOOZH | about |
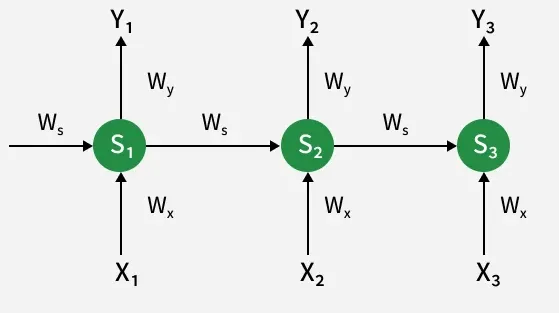
Recurrent Neural Networks (RNNs) are designed for sequential data such as text, speech and time series. Unlike traditional neural networks, RNNs use an internal memory (hidden state) so the output depends on both current and previous inputs.
At each timestep , the RNN maintains a hidden state , that stores information from previous inputs. The hidden state updates by combining the current input and the previous hidden state , applying an activation function to introduce non-linearity. Then the output is generated by transforming this hidden state.
where and are activation functions.
To train the network, we measure how far the predicted output is from the desired output using an error function. We use the squared error to measure the difference between the desired output and actual output :
At :
This error quantifies the difference between the predicted output and the actual output at time 3.
Backpropagation Through Time (BPTT) updates the weights by computing gradients across multiple time steps to minimize error.
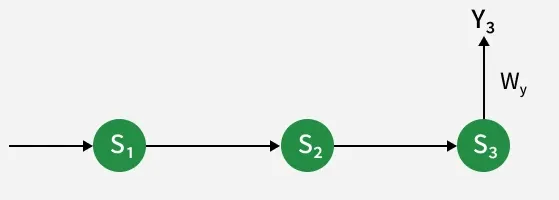
The output weight directly affects the current output , so its update depends only on the current time step.
Using the chain rule:
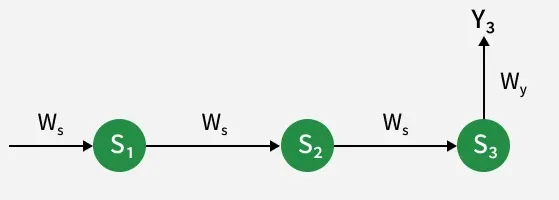
The hidden state weight affects both the current and previous hidden states because each hidden state depends on the one before it. Therefore, updating , requires considering how all hidden states influence the output at time step 3.
Gradient Flow Through Hidden States
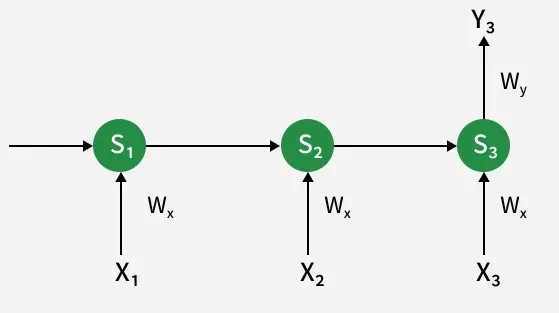
Similar to , the input weight affects all hidden states because the input at each timestep shapes the hidden state. The process considers how every input in the sequence impacts the hidden states leading to the output at time 3.
The process is similar to , accounting for all previous hidden states because inputs at each timestep affect the hidden states.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}