 |
VOOZH | about |
|
VOOZH | about |
The concept of a hypothesis is fundamental in Machine Learning and data science endeavours. In the realm of machine learning, a hypothesis serves as an initial assumption made by data scientists and ML professionals when attempting to address a problem. Machine learning involves conducting experiments based on past experiences, and these hypotheses are crucial in formulating potential solutions.
It's important to note that in machine learning discussions, the terms "hypothesis" and "model" are sometimes used interchangeably. However, a hypothesis represents an assumption, while a model is a mathematical representation employed to test that hypothesis. This section on "Hypothesis in Machine Learning" explores key aspects related to hypotheses in machine learning and their significance.
Table of Content
A hypothesis in machine learning is the model's presumption regarding the connection between the input features and the result. It is an illustration of the mapping function that the algorithm is attempting to discover using the training set. To minimize the discrepancy between the expected and actual outputs, the learning process involves modifying the weights that parameterize the hypothesis. The objective is to optimize the model's parameters to achieve the best predictive performance on new, unseen data, and a cost function is used to assess the hypothesis' accuracy.
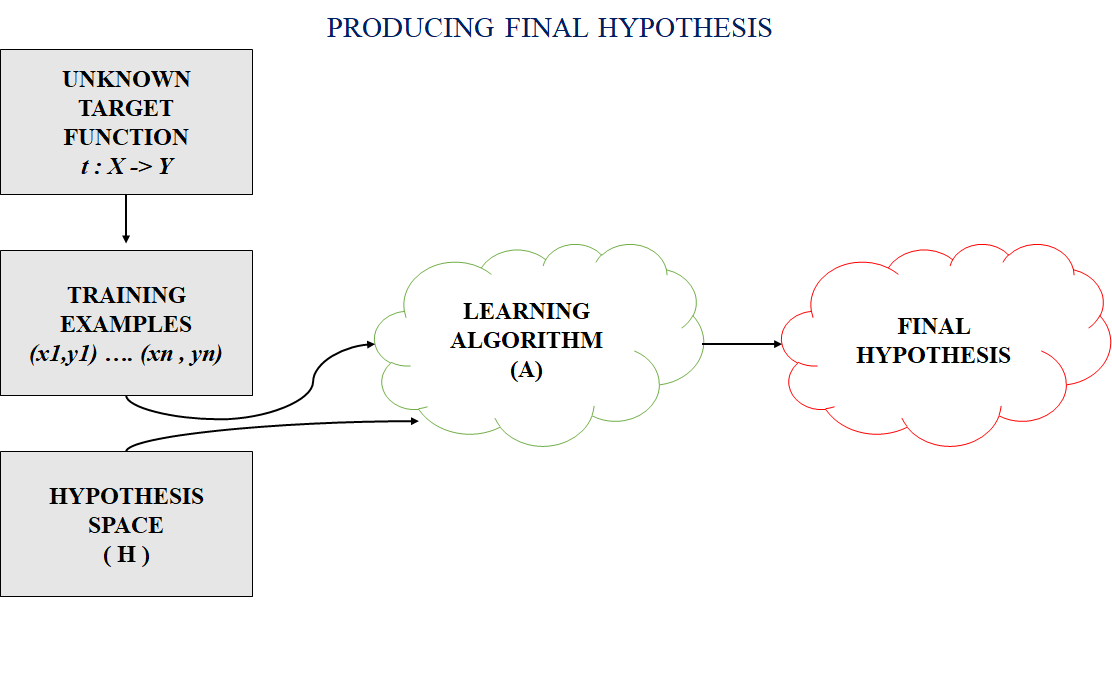
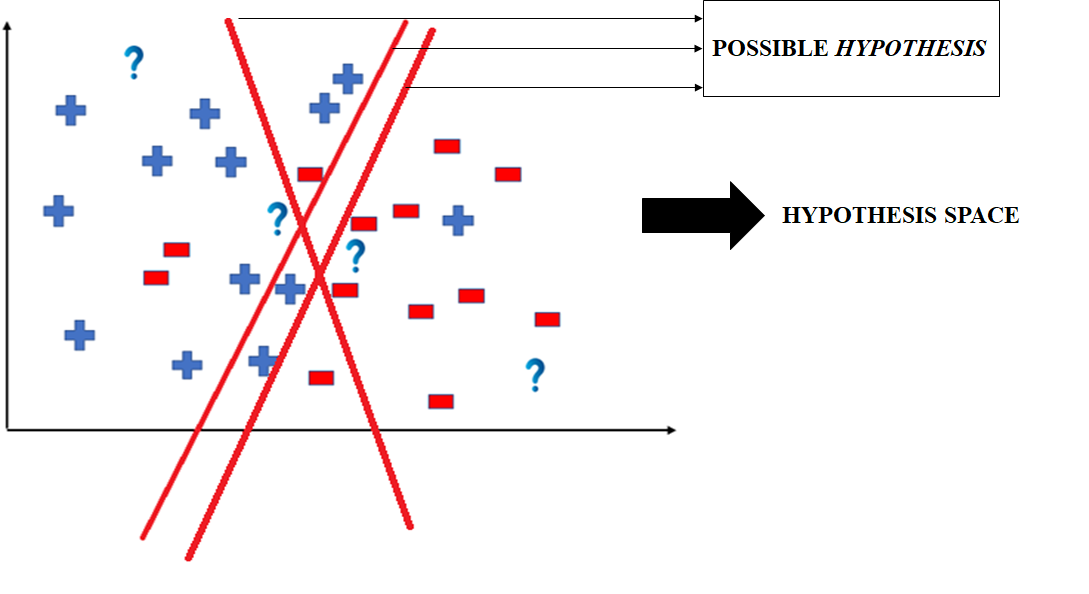
In most supervised machine learning algorithms, our main goal is to find a possible hypothesis from the hypothesis space that could map out the inputs to the proper outputs. The following figure shows the common method to find out the possible hypothesis from the Hypothesis space:
👁 Hypothesis-GeeksforgeeksHypothesis space is the set of all the possible legal hypothesis. This is the set from which the machine learning algorithm would determine the best possible (only one) which would best describe the target function or the outputs.
A hypothesis is a function that best describes the target in supervised machine learning. The hypothesis that an algorithm would come up depends upon the data and also depends upon the restrictions and bias that we have imposed on the data.
The Hypothesis can be calculated as:
Where,
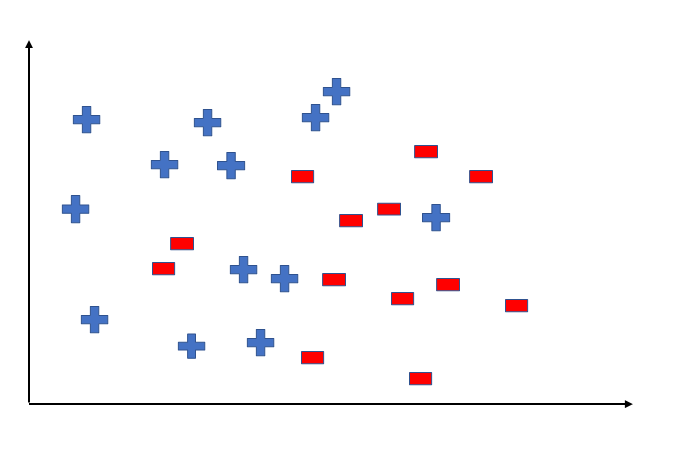
To better understand the Hypothesis Space and Hypothesis consider the following coordinate that shows the distribution of some data:
👁 Hypothesis_GeeksforgeeksSay suppose we have test data for which we have to determine the outputs or results. The test data is as shown below:
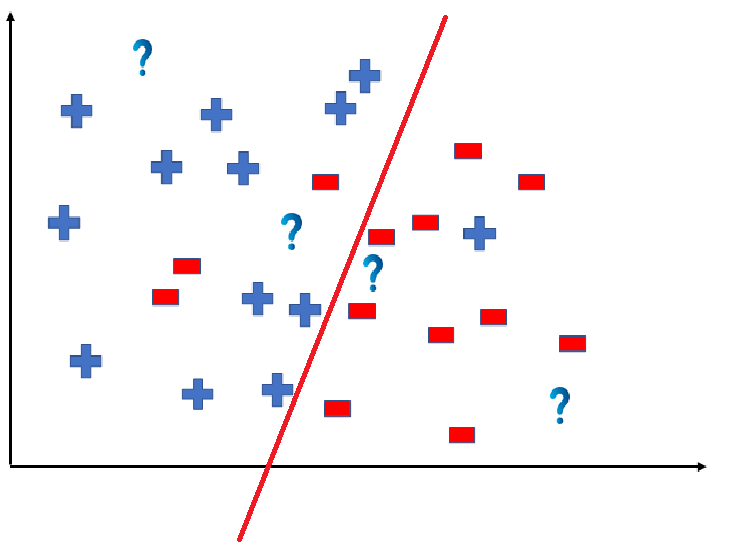
👁 ImageWe can predict the outcomes by dividing the coordinate as shown below:
👁 ImageSo the test data would yield the following result:
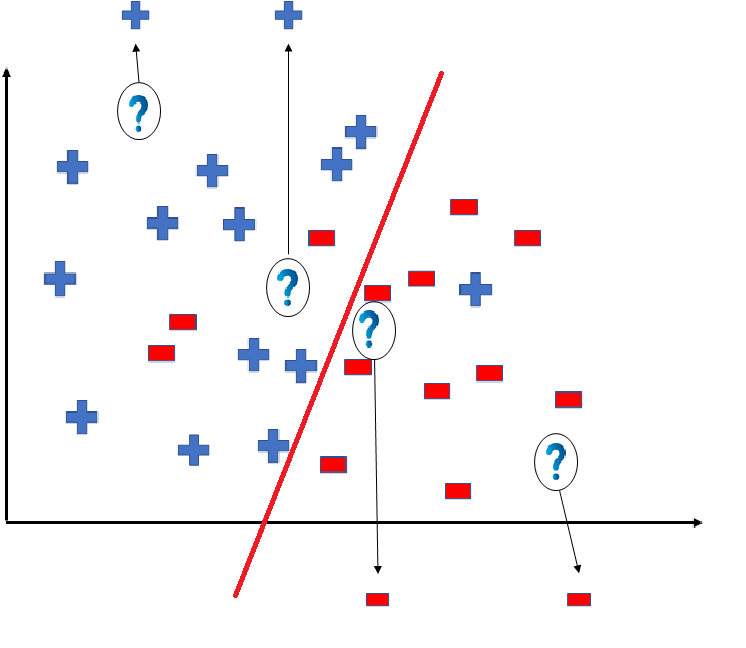
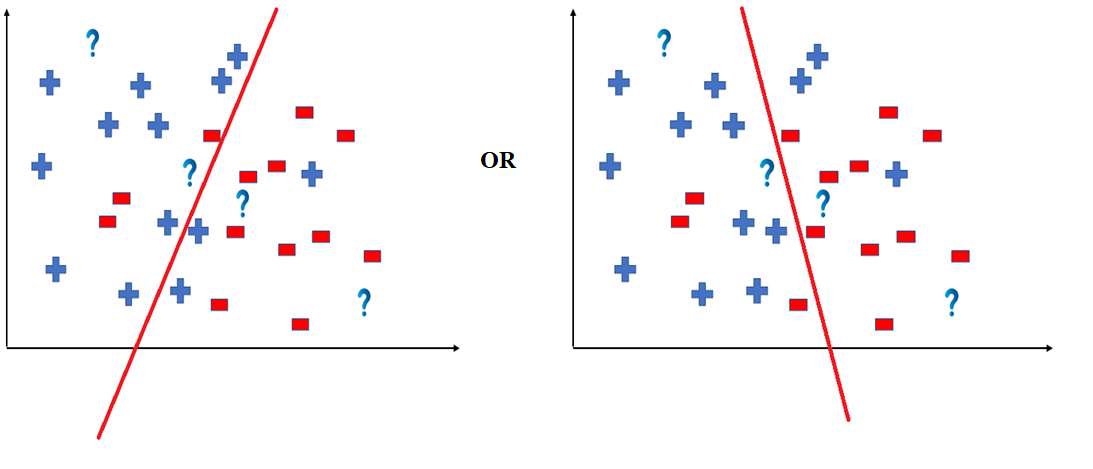
👁 ImageBut note here that we could have divided the coordinate plane as:
👁 ImageThe way in which the coordinate would be divided depends on the data, algorithm and constraints.
Hence, in this example the hypothesis space would be like:
👁 Possible hypothesis-GeeksforgeeksThe hypothesis space comprises all possible legal hypotheses that a machine learning algorithm can consider. Hypotheses are formulated based on various algorithms and techniques, including linear regression, decision trees, and neural networks. These hypotheses capture the mapping function transforming input data into predictions.
Hypotheses in machine learning are formulated based on various algorithms and techniques, each with its representation. For example:
In the case of complex models like neural networks, the hypothesis may involve multiple layers of interconnected nodes, each performing a specific computation.
The process of machine learning involves not only formulating hypotheses but also evaluating their performance. This evaluation is typically done using a loss function or an evaluation metric that quantifies the disparity between predicted outputs and ground truth labels. Common evaluation metrics include mean squared error (MSE), accuracy, precision, recall, F1-score, and others. By comparing the predictions of the hypothesis with the actual outcomes on a validation or test dataset, one can assess the effectiveness of the model.
Once a hypothesis is formulated and evaluated, the next step is to test its generalization capabilities. Generalization refers to the ability of a model to make accurate predictions on unseen data. A hypothesis that performs well on the training dataset but fails to generalize to new instances is said to suffer from overfitting. Conversely, a hypothesis that generalizes well to unseen data is deemed robust and reliable.
The process of hypothesis formulation, evaluation, testing, and generalization is often iterative in nature. It involves refining the hypothesis based on insights gained from model performance, feature importance, and domain knowledge. Techniques such as hyperparameter tuning, feature engineering, and model selection play a crucial role in this iterative refinement process.
In statistics, a hypothesis refers to a statement or assumption about a population parameter. It is a proposition or educated guess that helps guide statistical analyses. There are two types of hypotheses: the null hypothesis (H0) and the alternative hypothesis (H1 or Ha).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}