 |
VOOZH | about |
|
VOOZH | about |
Multiclass Classification and Multi‑Label Classification are two important approaches used to categorize data but they differ in how many classes an instance can belong to. In multiclass classification, each input is assigned to only one class, while in multi‑label classification, an input can be associated with multiple classes at the same time. Understanding this distinction is essential for choosing the right model for real‑world tasks.
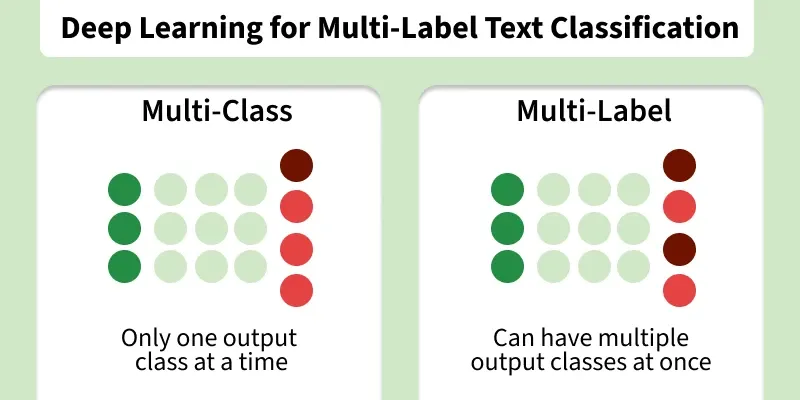
Multiclass classification is a type of supervised learning problem where each data instance is assigned to exactly one class out of three or more mutually exclusive classes. In this setting, an instance cannot belong to more than one class at the same time. The model learns to discriminate among all possible classes and predicts the single most probable class for each input.
For example, in a handwritten digit recognition task, an image can represent only one digit (0–9) at a time. Even though multiple classes exist, the prediction is restricted to exactly one label.
Multi-label classification is a supervised learning problem where each data instance can be assigned multiple labels simultaneously. Unlike multiclass classification, labels are not mutually exclusive and the presence of one label does not prevent the presence of another.
For example, a movie can belong to multiple genres such as action, thriller and sci-fi at the same time. The model predicts a set of relevant labels rather than a single class.
Let's see the comparison between Multiclass and Multi-Label Classification:
| Aspect | Multiclass Classification | Multi-Label Classification |
|---|---|---|
| Label assignment | Each data instance is assigned only one label from the available classes | Each data instance can be assigned multiple relevant labels at the same time |
| Class relationship | Classes are mutually exclusive, meaning choosing one excludes all others | Classes are not mutually exclusive and can overlap |
| Output representation | The model outputs a single class as the final prediction | The model outputs a set of labels or a binary vector |
| Probability distribution | The predicted probabilities across classes sum to one, enforcing competition | Each label is predicted independently, with no summation constraint |
| Activation function | Softmax is commonly used to select the most probable class | Sigmoid is commonly used to estimate probability for each label |
| Decision boundaries | A single decision space separates all classes | Separate decision boundaries exist for each label |
| Error interpretation | A wrong prediction means the entire output is incorrect | Predictions can be partially correct if some labels match |
| Model complexity | Simpler to design and train due to one output per instance | More complex due to multiple outputs and label dependencies |
| Evaluation metrics | Accuracy and confusion matrix are commonly sufficient | Metrics like Hamming Loss and Micro/Macro F1 are required |
| Typical applications | Used where only one category applies, such as digit recognition | Used where multiple categories apply, such as text tagging |
{kind=link}
{kind=link}