 |
VOOZH | about |
|
VOOZH | about |
Today there are no certain methods by using which we can predict whether there will be rainfall today or not. Even the meteorological department's prediction fails sometimes. In this article, we will learn how to build a machine-learning model which can predict whether there will be rainfall today or not based on some atmospheric factors. This problem is related to Rainfall Prediction using Machine Learning because machine learning models tend to perform better on the previously known task which needed highly skilled individuals to do so.
Python libraries make it easy for us to handle the data and perform typical and complex tasks with a single line of code.
Now let's load the dataset into the panda's data frame and print its first five rows.
Output:
Now let's check the size of the dataset.
Output:
(366, 12)Let's check which column of the dataset contains which type of data.
Output:
As per the above information regarding the data in each column, we can observe that there are no null values.
Output:
The data which is obtained from the primary sources is termed the raw data and required a lot of preprocessing before we can derive any conclusions from it or do some modeling on it. Those preprocessing steps are known asdata cleaning and it includes, outliers removal, null value imputation, and removing discrepancies of any sort in the data inputs.
Output:
So there is one null value in the 'winddirection' as well as the 'windspeed' column. But what's up with the column name wind direction?
Output:
Index(['day', 'pressure ', 'maxtemp', 'temperature', 'mintemp', 'dewpoint',
'humidity ', 'cloud ', 'rainfall', 'sunshine', ' winddirection',
'windspeed'],
dtype='object')Here we can observe that there are unnecessary spaces in the names of the columns let's remove that.
Output:
Index(['day', 'pressure', 'maxtemp', 'temperature', 'mintemp', 'dewpoint',
'humidity', 'cloud', 'rainfall', 'sunshine', 'winddirection',
'windspeed'],
dtype='object')Now it's time for null value imputation.
Output:
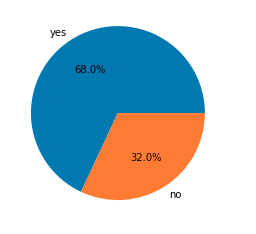
0EDA is an approach to analyzing the data using visual techniques. It is used to discover trends, and patterns, or to check assumptions with the help of statistical summaries and graphical representations. Here we will see how to check the data imbalance and skewness of the data.
Output:
Output:
Here we can clearly draw some observations:
The observations we have drawn from the above dataset are very much similar to what is observed in real life as well.
Output:
['pressure', 'maxtemp', 'temperature', 'mintemp', 'dewpoint', 'humidity', 'cloud', 'sunshine', 'winddirection', 'windspeed']Let's check the distribution of the continuous features given in the dataset.
Output:
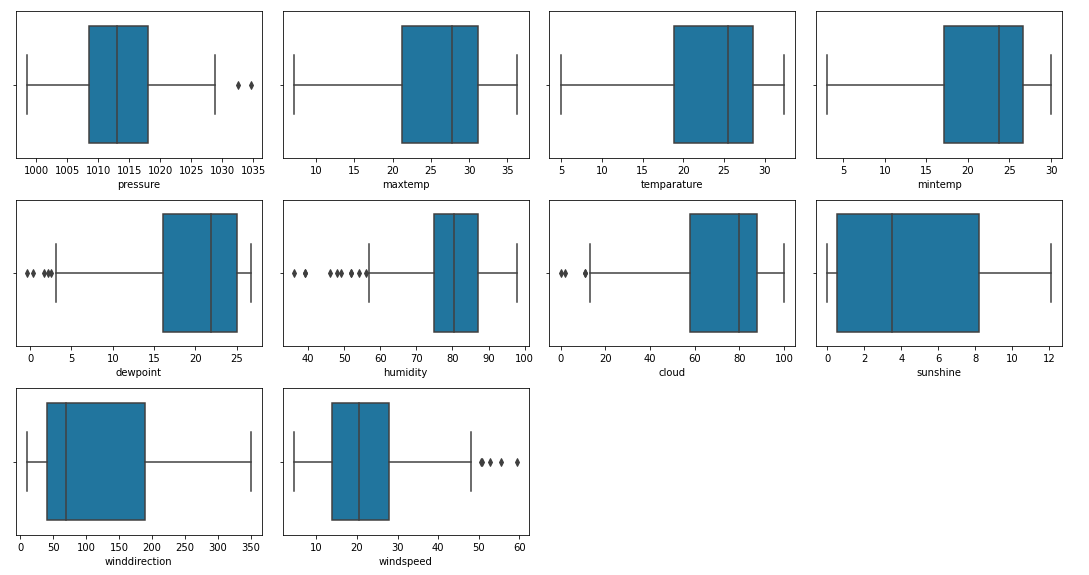
Let's draw boxplots for the continuous variable to detect the outliers present in the data.
Output:
There are outliers in the data but sadly we do not have much data so, we cannot remove this.
Sometimes there are highly correlated features that just increase the dimensionality of the feature space and do not good for the model's performance. So we must check whether there are highly correlated features in this dataset or not.
Output:
Now we will remove the highly correlated features 'maxtemp' and 'mintemp'. But why not temp or dewpoint? This is because temp and dewpoint provide distinct information regarding the weather and atmospheric conditions.
Now we will separate the features and target variables and split them into training and testing data by using which we will select the model which is performing best on the validation data.
As we found earlier that the dataset we were using was imbalanced so, we will have to balance the training data before feeding it to the model.
The features of the dataset were at different scales so, normalizing it before training will help us to obtain optimum results faster along with stable training.
Now let's train some state-of-the-art models for classification and train them on our training data.
Output:
LogisticRegression() :
Training Accuracy : 0.8893967324057472
Validation Accuracy : 0.8966666666666667
XGBClassifier() :
Training Accuracy : 0.9903285270573975
Validation Accuracy : 0.8408333333333333
SVC(probability=True) :
Training Accuracy : 0.9026413474407211
Validation Accuracy : 0.8858333333333333From the above accuracies, we can say that Logistic Regression and support vector classifier are satisfactory as the gap between the training and the validation accuracy is low. Let's plot the confusion matrix as well for the validation data using the SVC model.
Output:
Let's plot the classification report as well for the validation data using the SVC model.
Output:
precision recall f1-score support
0 0.84 0.67 0.74 24
1 0.85 0.94 0.90 50
accuracy 0.85 74
macro avg 0.85 0.80 0.82 74
weighted avg 0.85 0.85 0.85 741. Notebook Link: click here.
2. Dataset Link: click here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}