 |
VOOZH | about |
|
VOOZH | about |
Data augmentation in NLP is a technique used to create additional training data by slightly modifying existing text. This helps machine learning models perform better, especially when the original dataset is small. Whether we're building a model for text classification, summarization or question answering, data augmentation can make a big difference.
Some common techniques used for data augmentation in NLP include:
In this article, we'll focus on how the Text-to-Text Transfer Transformer (T5) can be used to generate new training data and improve NLP model performance.
Text-to-Text Transfer Transformer (T5) is a large transformer model trained on the Colossal Clean Crawled Corpus (C4). It was released as a pre-trained model capable of handling various NLP tasks such as translation, summarization, question answering and classification.
T5 treats every NLP task as a text-to-text problem. This means both the input and output are plain text, regardless of the task. For example:
Example 1: For English-to-German translation, the input could be: "translate English to German: That is a book." then the output would be the translated sentence in German.
Example 2: For sentiment analysis, the input might be: "sentiment analysis: I love this product." and the output would be: "positive".
T5 allows training on multiple tasks by using different prefixes in the input to indicate the task type. This approach enables a single model to handle diverse NLP tasks effectively. It has shown strong performance across many benchmarks and is widely used for generating synthetic data in data augmentation workflows.
There are multiple ways to use the T5 (Text-to-Text Transfer Transformer) model for data augmentation in NLP tasks.
Similar to back translation, T5 can be used without additional training by leveraging its pre-trained summarization capabilities. In this approach:
T5 can also be fine-tuned on specific tasks to generate high-quality synthetic data. Two effective strategies are:
"generate paraphrase: <sentence>" and output as its paraphrase.T5 is available in multiple sizes:
T5-Small (60M parameters)T5-Base (220M)T5-Large (770M)T5-3B (3 billion)T5-11B (11 billion)Larger models tend to produce better results but require more computational resources and training time. However, this is typically a one-time effort and the resulting model can be reused across various NLP tasks for effective data augmentation.
transformers, pytorch and pandasAutomatically use GPU if available, otherwise fall back to CPU
Output:
Using device: cpu
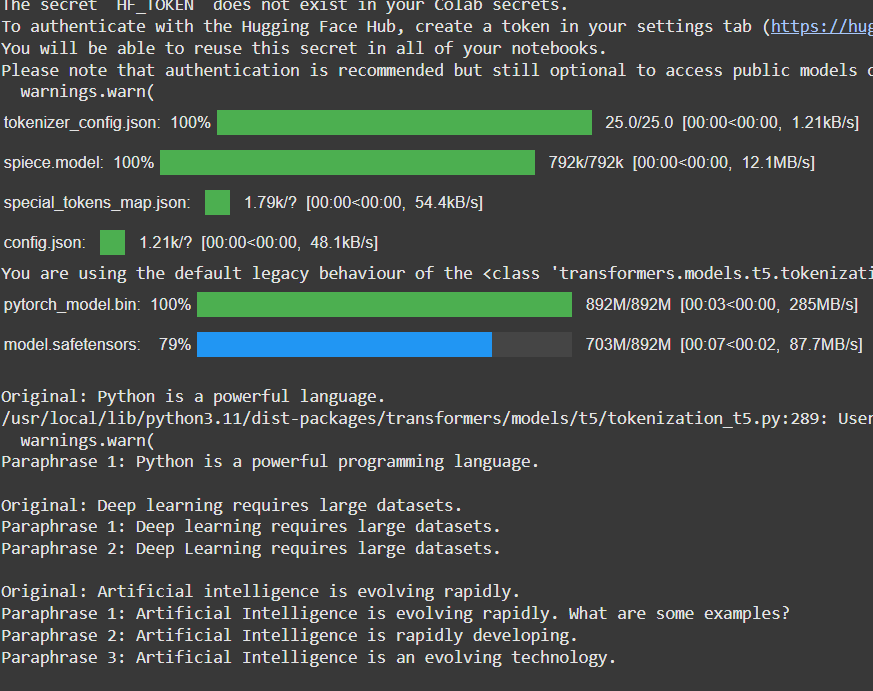
"paraphrase:" prompt.Output:
Output:
Output:
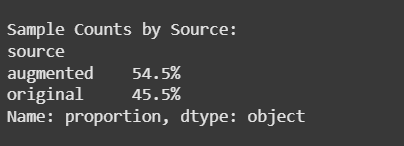
Show proportion of original vs. augmented data
Output:
Here we can see that our model is working fine.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}