 |
VOOZH | about |
|
VOOZH | about |
The sinking of the RMS Titanic in 1912 remains one of the most infamous maritime disasters in history, leading to significant loss of life. Over 1,500 passengers and crew perished that fateful night. Understanding the factors that contributed to survival can provide valuable insights into safety protocols and social dynamics during crises. In this project, we will leverage machine learning techniques to predict the survival chances of Titanic passengers based on various features, such as sex, age, and passenger class. Using the Random Forest classification algorithm, we aim to build a predictive model that will allow us to estimate the likelihood of survival for each individual aboard the Titanic.
Table of Content
The primary objective of this project is to develop a machine learning model capable of predicting the survival status of Titanic passengers based on available data. The dataset includes information such as demographic attributes (age, sex), socioeconomic status (fare, class), and other relevant features. By analyzing these features, we seek to identify patterns that could influence survival rates and subsequently use these insights to make predictions on unseen data.
There will be three main steps in this experiment:
For this project, we will utilize the Titanic dataset. The dataset consists of the following files:
Now let's read the training and test data using the pandas data frame.
To know the information about each column like the data type, etc we use the df.info() function.
Output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
Now let's see if there are any NULL values present in the dataset. This can be checked using the isnull() function. It yields the following output.
Output:
memory usage: 83.7+ KB
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
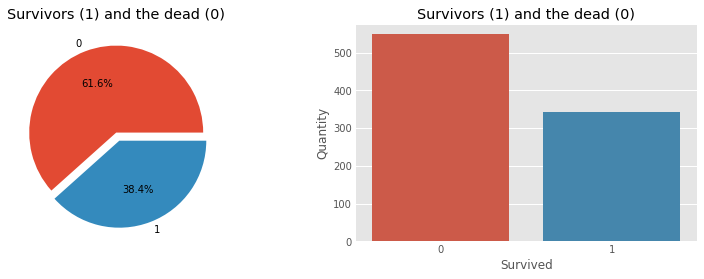
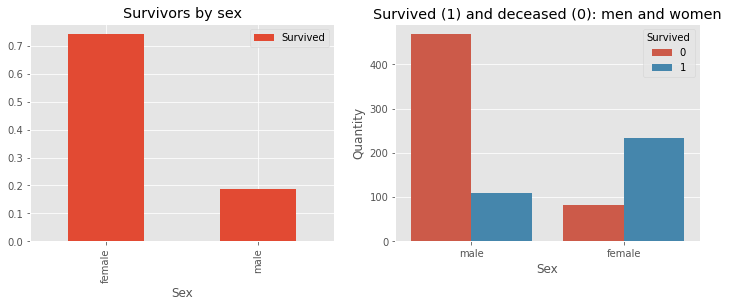
Now let us visualize the data using some pie charts and histograms to get a proper understanding of the data.
Output:
Output:
This section focuses on refining the dataset by removing irrelevant features and transforming categorical data into numerical formats. Key tasks include:
Cabin that offer limited predictive value.We can also drop the Ticket feature since it's unlikely to yield any useful information.
There are missing values in the Embarked feature. For that, we will replace the NULL values with 'S' as the number of Embarks for 'S' are higher than the other two.
We will now sort the age into groups. We will combine the age groups of the people and categorize them into the same groups. BY doing so we will be having fewer categories and will have a better prediction since it will be a categorical dataset.
In the 'title' column for both the test and train set, we will categorize them into an equal number of classes. Then we will assign numerical values to the title for convenience of model training.
Now using the title information we can fill in the missing age values.
Now assign a numerical value to each age category. Once we have mapped the age into different categories we do not need the age feature. Hence drop it
Drop the name feature since it contains no more useful information.
Assign numerical values to sex and embarks categories\
Fill in the missing Fare value in the test set based on the mean fare for that P-class
Now we are done with the feature engineering.
In this phase, we employ Random Forest as our algorithm to train the model for predicting survival. Key steps include:
train_test_split() from the sklearn library.Now import the random forest function from the ensemble module of sklearn and for the training set.
Output:
83.8With this, we got an accuracy of 83.8%
In this final phase, we use the trained Random Forest model to make predictions on the test dataset. The key steps are:
This will create a resultfile.csv which looks like this:
In this project, we successfully built a Random Forest classifier to predict the survival chances of Titanic passengers. Through data preprocessing, feature engineering, imputation, and model training, we were able to create a robust model with 83.8% accuracy on the training set.
{kind=link}
{kind=link}
{kind=link}
{kind=link}