 |
VOOZH | about |
|
VOOZH | about |
LightGBM is a tree-based ensemble learning algorithm that uses gradient boosting. Unlike traditional boosting methods, it grows trees leaf-wise (best-first) instead of level-wise.
Note: Leaf-wise growth can lead to overfitting, but this is controlled using parameters like max_depth.
LightGBM converts continuous data into discrete bins, which:
Instead of splitting all nodes level by level, LightGBM:
To train a model using LightGBM we need to install it to our runtime.
!pip install lightgbm
Importing required libraries
We import all required Python libraries like NumPy, Pandas, Seaborn, Matplotlib and SKlearn etc.
The dataset is loaded and split into training and testing sets using stratified sampling to maintain class balance.
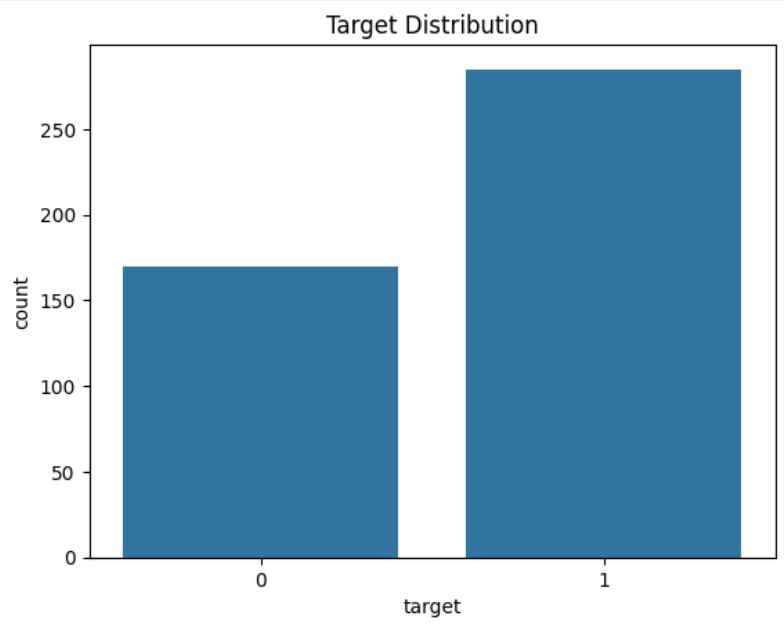
Target Distribution: This plot helps check whether the dataset is balanced or imbalanced.
Output:
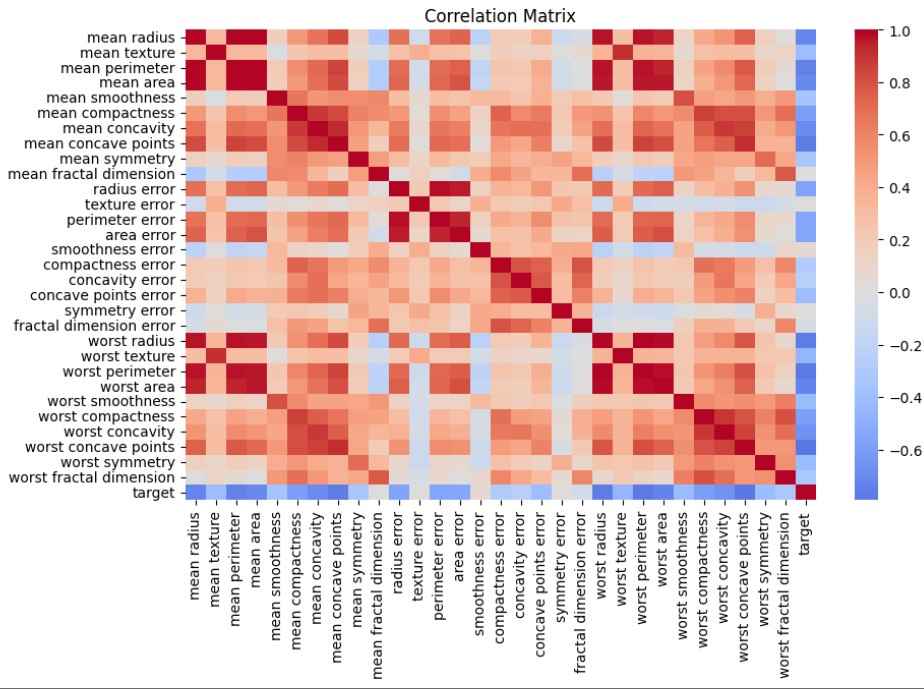
Correlation Matrix: The heatmap shows relationships between features and helps identify highly correlated variables.
Output:
LightGBM uses its own optimized dataset format for faster training and better memory usage.
These parameters control model learning, complexity, regularization and performance.
The model is trained with early stopping to prevent overfitting and logging disabled for cleaner output.
Output:
Training until validation scores don't improve for 50 rounds
Early stopping, best iteration is:
[22] train's auc: 0.996956 train's binary_logloss: 0.238247 valid's auc: 0.993056 valid's binary_logloss: 0.257051
The model outputs probabilities, which are converted into binary predictions using a threshold of 0.5.
These metrics evaluate model performance from different perspectives, especially AUC for classification quality.
Output:
Accuracy: 0.9473684210526315
Precision: 0.9583333333333334
Recall: 0.9583333333333334
F1 Score: 0.9583333333333334
AUC: 0.9930555555555556
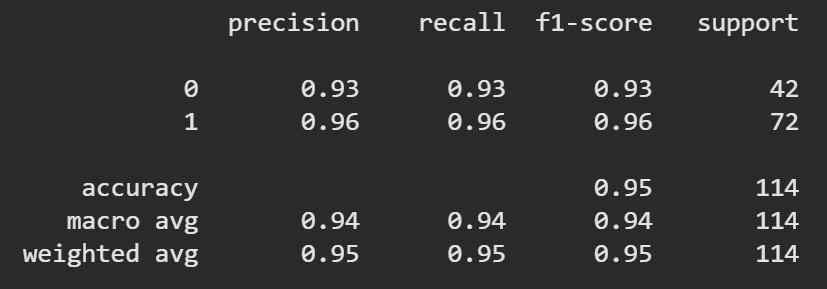
Provides a detailed summary of precision, recall and F1-score for each class.
Output:
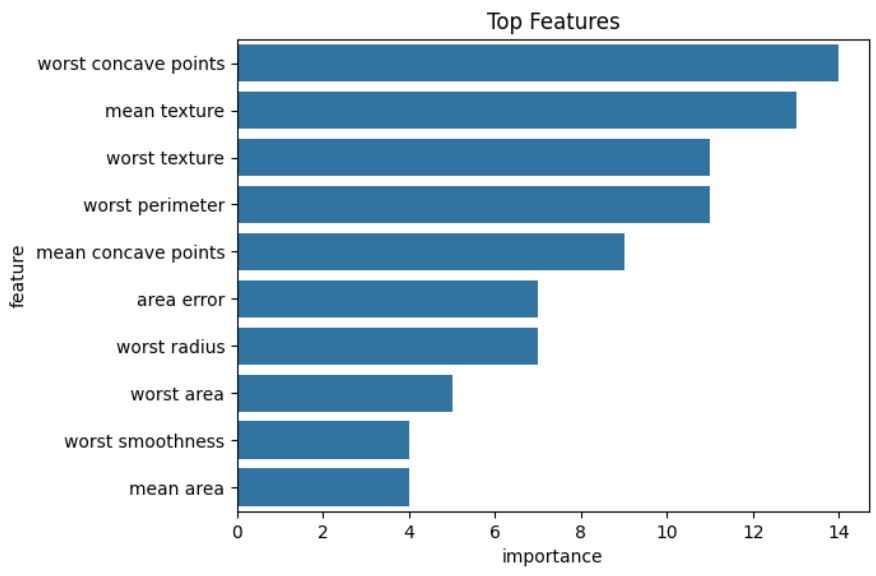
Shows which features contribute most to the model’s predictions.
Output:
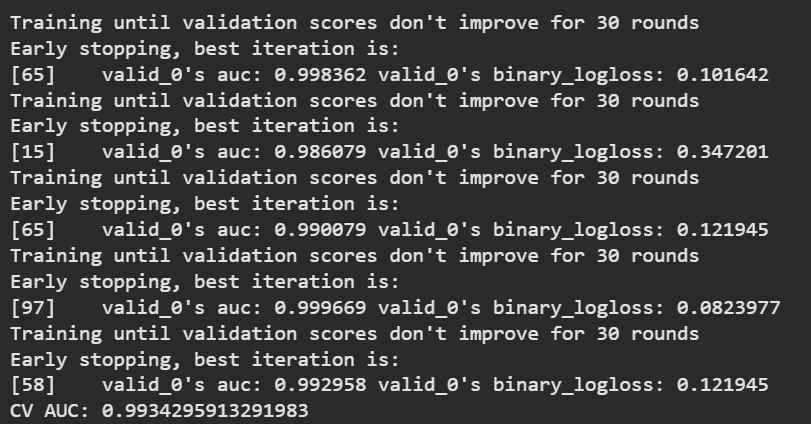
Cross-validation ensures the model performs well across different data splits (more reliable than a single train-test split).
Output:
You can download the source code from here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}