 |
VOOZH | about |
|
VOOZH | about |
When building machine learning models like decision trees, imbalanced data—where one class significantly outnumbers another—presents a unique challenge. For example, in credit card transactions, legitimate transactions may vastly outnumber fraudulent ones. Without adjustments, decision trees tend to favor the majority class, often misclassifying the minority class.
Decision trees are effective classifiers, constructing logical rules to separate classes. However, on imbalanced datasets, trees tend to maximize node purity, leading them to favor the majority class at the expense of the minority class due to: Decision trees often emphasize the more frequent class, which can lead to high misclassification rates for the minority class.
Consider a decision tree classifying medical records as healthy or diseased. With 99.5% healthy cases, the tree may default to "healthy" predictions, yielding high accuracy but misclassifying all diseased cases. By applying cost-sensitive learning or alternative splitting criteria, the tree can prioritize correct classification of the minority diseased cases.
Let's now see a code example in this scenario:
This code generates an imbalanced synthetic dataset with three classes using make_classification, with class distribution controlled by the weights parameter (70%, 20%, and 10% for each class). It then displays the class distribution and splits the data into training and testing sets, preparing it for training a classification model.
Output:
Class distribution: Counter({np.int64(0): 700, np.int64(1): 200, np.int64(2): 100})
This code initializes a decision tree classifier with balanced class weights to address imbalanced data, sets a controlled depth (max_depth=4) and minimum leaf samples for stability. After training, it evaluates the model with precision, recall, and F1 scores, and calculates the ROC AUC score using a one-vs-rest approach for multi-class. Finally, it displays the confusion matrix and visualizes the decision tree structure.
Output:
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 217
1 1.00 0.98 0.99 56
2 0.96 1.00 0.98 27
accuracy 1.00 300
macro avg 0.99 0.99 0.99 300
weighted avg 1.00 1.00 1.00 300
ROC AUC Score: 1.00
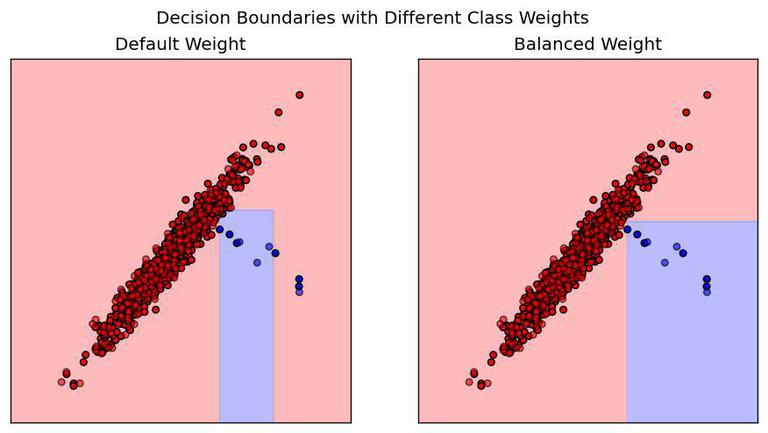
The benefit of using balanced trees can be observed in the following decision boundaries:
{kind=link}
{kind=link}