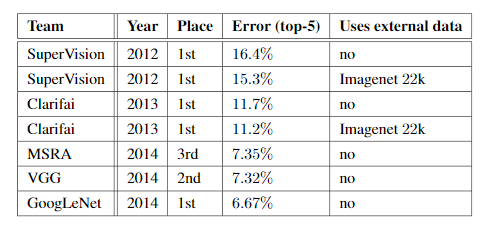
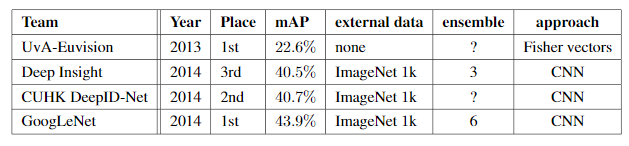
GoogLeNet (Inception V1) is a convolutional neural network designed for efficient image classification. It uses the Inception module to process multiple filter sizes in parallel, improving feature extraction while keeping computation low.
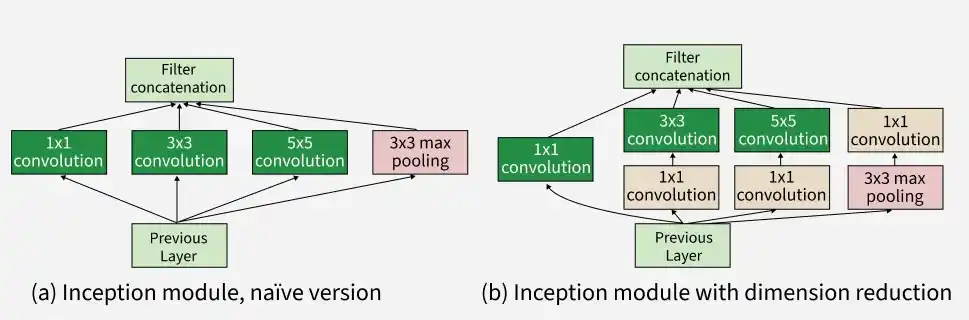
Inception modules combine 1×1, 3×3, 5×5 convolutions and pooling in parallel
Uses 1×1 convolutions and global average pooling to reduce computation and parameters
Designed to achieve high accuracy with efficient use of resources
Key Features of GoogLeNet
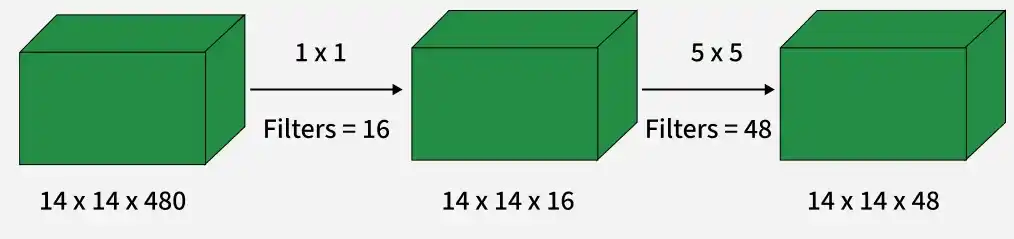
1. 1×1 Convolutions
GoogLeNet uses 1×1 convolutions mainly for dimensionality reduction, which reduces computation and the number of trainable parameters while preserving important features.
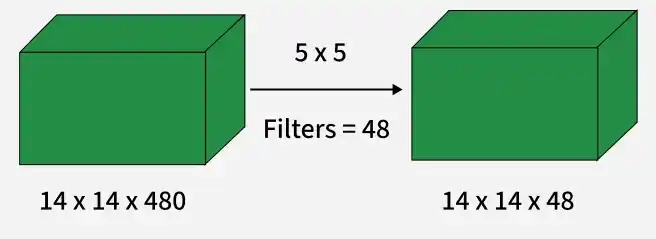
Example Comparison:
Without 1×1 Convolution:(14×14×48)×(5×5×480)=112.9M operation
To reduce vanishing gradient problems, GoogLeNet uses auxiliary classifiers during training.
Each classifier includes:
Average pooling
1×1 convolution
Fully connected layers
Softmax output
These help stabilize training and improve generalization.
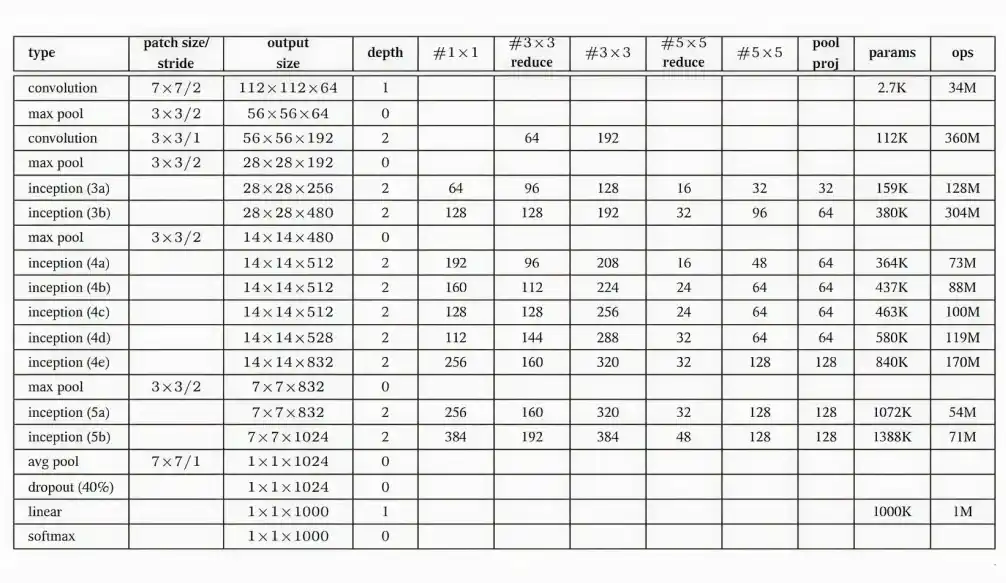
5. Model Architecture
GoogLeNet is a 22-layer deep network (excluding pooling layers) that emphasizes computational efficiency, making it feasible to run even on hardware with limited resources. Below is Layer by Layer architectural details of GoogLeNet.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}