 |
VOOZH | about |
|
VOOZH | about |
Non-parametric methods in statistics are techniques that do not assume a specific probability distribution for the data. Unlike parametric methods, which rely on fixed parameters (e.g., mean, variance), non-parametric methods are more flexible and useful when dealing with unknown or complex distributions. These methods are widely applied in hypothesis testing, regression, density estimation and classification.
Used to compare two independent groups when normality assumptions do not hold.
where:
Output
Mann-Whitney U test statistic: 10.0 p-value: 0.6857142857142857
A non-parametric alternative to ANOVA for comparing more than two groups.
where:
Output
Kruskal-Wallis test statistic: 7.200000000000003 p-value: 0.02732372244729252
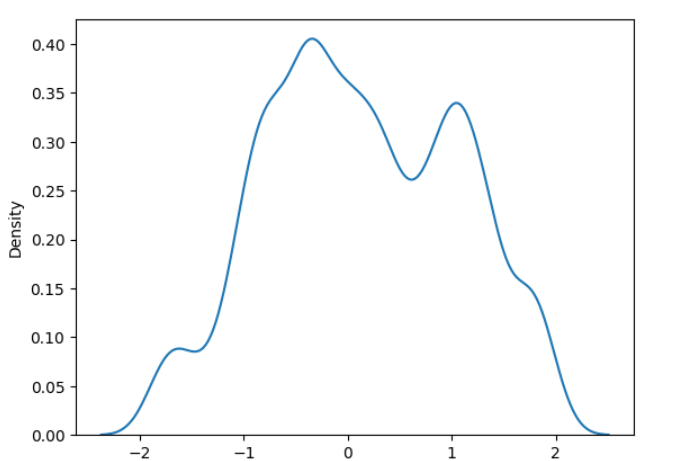
KDE is a technique to estimate the probability density function (PDF) of a dataset.
where:
Output
k-NN is a simple, non-parametric regression method that predicts the target variable based on the mean (or median) of the nearest k neighbors.
where yi are the values of the k nearest neighbors.
Implementation of K-Nearest Neighbors Regression
Output
[7.]
Bootstrap methods are resampling techniques used to estimate the sampling distribution of a statistic.
Output
Bootstrap Mean Estimate: 6.9883999999999995
{kind=link}
{kind=link}