Web scraping is the process of automatically extracting data from websites. It enables programmers to collect structured information from web pages without manual effort. In this article, we will demonstrate how to scrape data from the Wikipedia homepage using Python and discuss commonly used techniques, libraries for efficient web scraping.
The following Python libraries are commonly used to fetch, parse, and automate web pages during the web scraping process:
Requests: It is the foundation of web scraping in Python. It allows to send HTTP requests like GET and POST to download web pages quickly and reliably.
lxml:A high-performance library for parsing HTML and XML, lxml is extremely fast and ideal for large-scale scraping tasks.
BeautifulSoup: A beginner-friendly HTML parser that creates a parse tree for easy data extraction. It works seamlessly with content fetched using Requests.
Selenium: Automates a real browser, enabling scraping of dynamic, JavaScript-loaded websites. It is slower than other tools and less suitable for large-scale scraping.
Scrapy: A full-featured, asynchronous web scraping framework built for speed and scalability. It is ideal for large crawling projects, providing pipelines and advanced data handling capabilities.
Python Web Scraping on Wikipedia
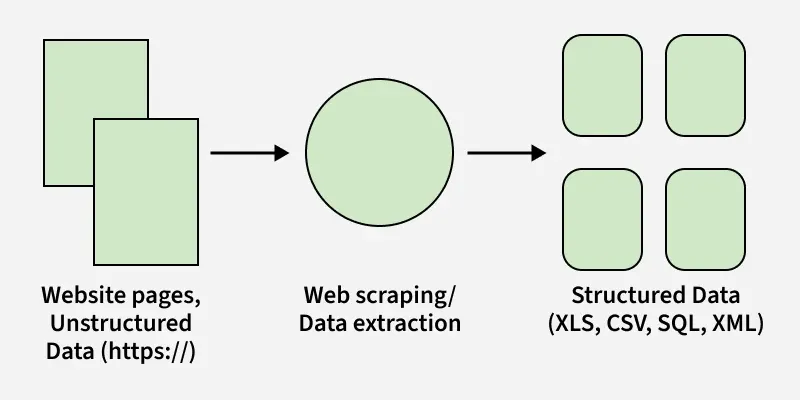
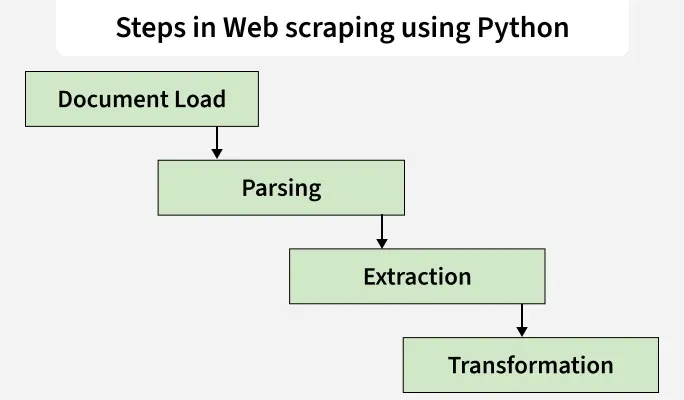
The following diagram shows the basic workflow followed when scraping data from Wikipedia using Python:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}