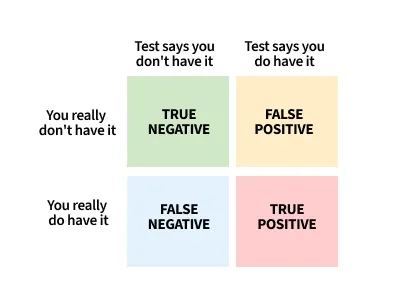
In machine learning and statistics, model evaluation plays a crucial role in determining the effectiveness of predictions. Two important types of errors are:
False Positive (FP): Incorrectly classifying a negative sample as positive.
False Negative (FN): Incorrectly classifying a positive sample as negative.
Both types of errors significantly impact model performance, especially in applications such as fraud detection, medical diagnosis and spam filtering.
False Positive (Type I Error)
A false positive occurs when the model incorrectly predicts a positive outcome for a sample that is actually negative.
Example of False Positive
Test Type: Spam email detection
True Condition: An email is not spam.
Prediction: The email is marked as spam.
Result: False positive.
False positives can result in Type I errors, meaning the null hypothesis is incorrectly rejected. In situations where false positives are frequent, the model may become overly sensitive, incorrectly identifying normal situations as problematic.
False Negative (Type II Error)
A false negative occurs when the model incorrectly predicts a negative outcome for a sample that is actually positive.
Example of False Negative
Test Type: Disease detection
True Condition: A person has the disease.
Prediction: The test indicates no disease.
Result: False negative.
False negatives are associated with Type II errors, meaning the null hypothesis is incorrectly accepted. High rates of false negatives often indicate that the model may be too conservative, failing to identify cases where action is needed.
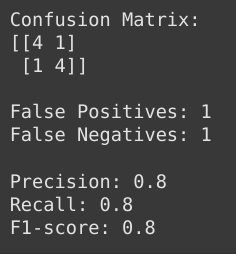
The precision (0.8), recall (0.8), and F1-score (0.8) indicate a balanced model performance with both false positives and false negatives contributing equally. A trade-off exists: optimizing to reduce one could increase the other, but the current values suggest that the model strikes a reasonable balance between these error

{kind=link}
{kind=link}
{kind=link}