Stacking is a technique in machine learning where we combine the predictions of multiple models to create a new model that can make better predictions than any individual model.
- In stacking, we first train several base models (also called first-layer models) on the training data.
- Then, a meta-model (also called final estimator) is trained using the predictions of the base models as input.
- The core idea is that if one model is sometimes right and another model is right in other cases, combining them intelligently can improve overall accuracy.
Step 1: Importing the required Libraries
We will import pandas, matplotlib and scikit learn for data handling, visualization and modeling.
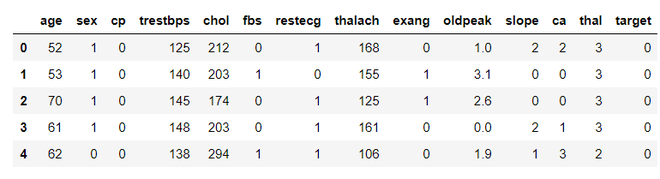
Step 2: Loading the Dataset
We will load the dataset into a pandas DataFrame and separate features from the target variable.
- pd.read_csv(): Reads the dataset from a CSV file.
- drop(): Removes the target column from features.
- df['target']: Selects the target column for prediction.
You can Download the dataset from this link Heart Dataset.
Output:
👁 ImageStep 3: Splitting the Data into Training and Testing Sets
We will split the dataset into training and testing sets so we can train models and evaluate their performance.
- train_test_split(): Splits data into train and test sets.
- test_size = 0.2: Specifies that 20% of the data should be used for testing, leaving 80% for training.
- random_state = 42: Ensures reproducibility by setting a fixed seed for random number generation.
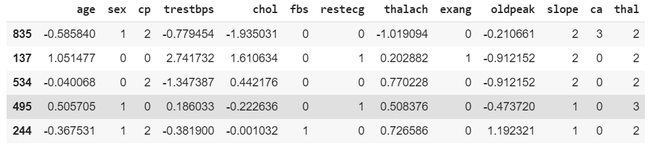
Step 4: Standardizing the Data
We will standardize numerical features so they have a mean of 0 and standard deviation of 1. This helps some models perform better.
- StandardScaler(): Standardizes features.
- fit_transform(): Learns scaling parameters from training data and applies them.
- transform(): Applies learned scaling to test data.
- var_transform: Specifies the list of feature columns that need to be standardized.
- X_train[var_transform]: Applies the fit_transform method to standardize the selected columns in the training data.
- X_test[var_transform]: Applies the transform method to standardize the corresponding columns in the test data using the scaling parameters from the training data.
Output:
👁 ImageStep 5: Building First Layer Estimators
We will create base models that will form the first layer of our stacking model. For this example we’ll use K-Nearest Neighbors classifier and Naive Bayes classifier.
- KNeighborsClassifier(): A model based on nearest neighbors.
- GaussianNB(): A Naive Bayes classifier assuming Gaussian distribution.
Step 6: Training and Evaluating KNeighborsClassifier
We will Train the KNN model and check its accuracy on the test set.
- fit(): Trains the model.
- predict(): Makes predictions on test data.
- accuracy_score(): Calculates accuracy
Output:
Accuracy Score of KNeighbors Classifier: 86.88524590163934
Step 7: Training and Evaluating Naive Bayes Classifier
Similarly, we will train the Naive Bayes model and check its accuracy.
Output:
Accuracy of Naive Bayes Classifier: 86.88524590163934
Step 8: Implementing the Stacking Classifier
Now, we will combine the base models using a Stacking Classifier. The meta-model will be a logistic regression model which will take the predictions of KNN and Naive Bayes as input.
- StackingClassifier(): Combines base models and a meta-model.
- classifiers: List of base learners.
- meta_classifier: Model that learns from base learners’ predictions.
- use_probas=True: Passes probability outputs to the meta-model instead of class labels.
Step 9: Training Stacking Classifier
Next we will rain the stacking classifier and evaluate its accuracy.
Output:
Accuracy Score of Stacked Model: 88.52459016393442
Both individual models (KNN and Naive Bayes) achieved an accuracy of approximately 86.88%, while the stacked model achieved an accuracy of around 88.52%. This shows that combining the predictions of multiple models using stacking can slightly improve overall performance compared to using a single model.
Related Articles

{kind=link}
{kind=link}
{kind=link}