 |
VOOZH | about |
|
VOOZH | about |
Affinity Propagation (AP) is a clustering algorithm that automatically identifies clusters and their exemplars (representative points) without requiring you to specify the number of clusters in advance. Unlike methods such as K-Means, Affinity Propagation determines cluster centers by iteratively exchanging “messages” between data points to identify the most suitable exemplars.
Suppose a dataset of fruits with features like color, size and weight. Affinity Propagation can group similar fruits:
Note: The algorithm does not require prior labels, it clusters purely based on similarity.
It starts with a similarity matrix s, where S(i,j) represents the similarity between points xi and xj .
By default, similarity is calculated as negative squared Euclidean distance:
Diagonal elements S(i,i) are called preferences, indicating how likely each point is to be chosen as an exemplar. A higher preference is more likely to become a cluster centre.
The responsibility matrix reflects how suitable a point is to be the exemplar for point , relative to other candidates:
A high means is much more suitable than any other candidate to represent .
The availability matrix represents how appropriate it is for to choose as its exemplar, considering the preferences of other points:
For :
For (self-availability):
Responsibility reflects a candidate’s suitability; availability reflects the support from other points.
and are updated iteratively until convergence.
Exemplars are points where:
Each point is then assigned to its nearest exemplar, forming clusters.
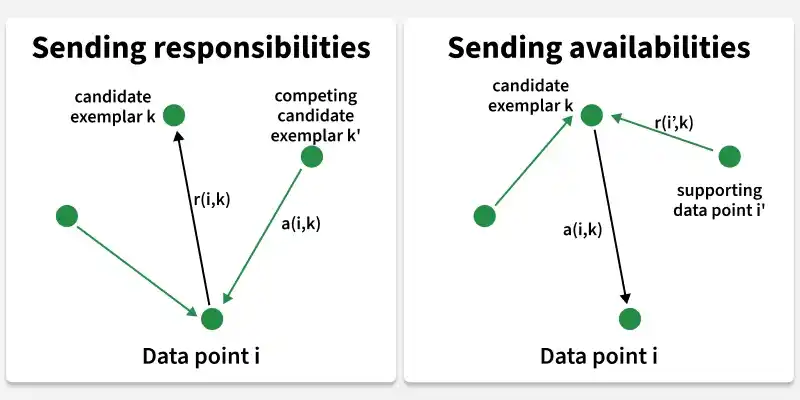
In Affinity Propagation, messages are passed between data points in two main steps:
Responsibility (Left Side): These messages shows how each data point communicates with its candidate exemplars. Each point sends responsibility messages to suggest how suitable it is to be chosen as an exemplar.
Availability (Right Side): These messages reflect how appropriate it is for each data point to choose its corresponding exemplar considering the support from other points. Essentially, these messages show how much support the candidate exemplars have.
There are mainly two parameters that influence the process of clustering.
Here we will see its step by step working:
At first we will import all required Python libraries like NumPy, Matplotlib, Seaborn, Pandas and Scikit learn.
Now we load the dataset for clustering. After that we will use to Standard Scaler to prepare the dataset for Affinity propagation.
You can download the dataset from here.
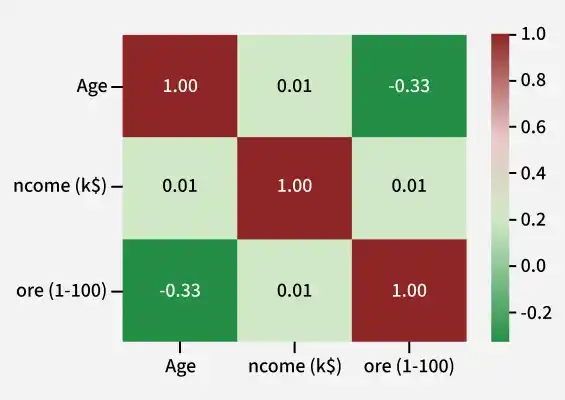
Exploratory Data Analysis (EDA) helps us to gain deeper insights about the dataset which is very important in clustering algorithm implementation.Visualizing correlation matrix will help us to understand how the features are correlated to each other.
Output:
So from it we can see that we can only select these three features. And as you can see we have only selected two features in our code of Data loading subsection.
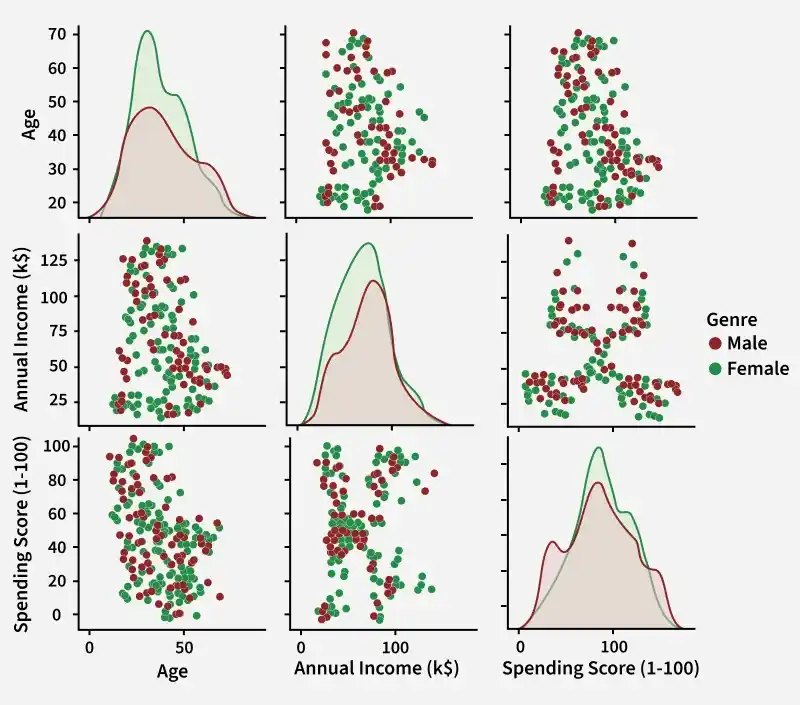
This plot grid shows scatter plots and histograms for every pair of features. It helps us understand feature distribution, relationships between variables and overall data patterns in a single view.
Output:
We now apply Affinity Propagation by setting its key parameters:
Output:
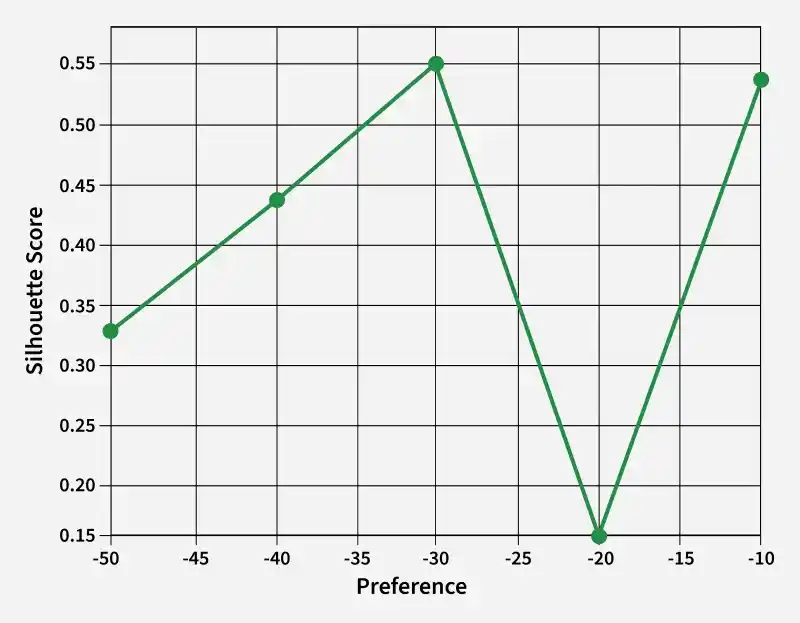
Here -30 resulting in higher value of preference parameter is the optimal preference.
We will apply Affinity Propagation to group the data points into clusters.
Output:
We will evaluate its performance using Silhouette Score.
Output:
Silhouette Score: 0.5529643053885619
Silhouette Score of 0.5529 represents a reasonably good degree of separation between the clusters. TA silhouette score > 0 indicates some separation between clusters, but not necessarily no overlap. Values closer to 1 represent better clustering.
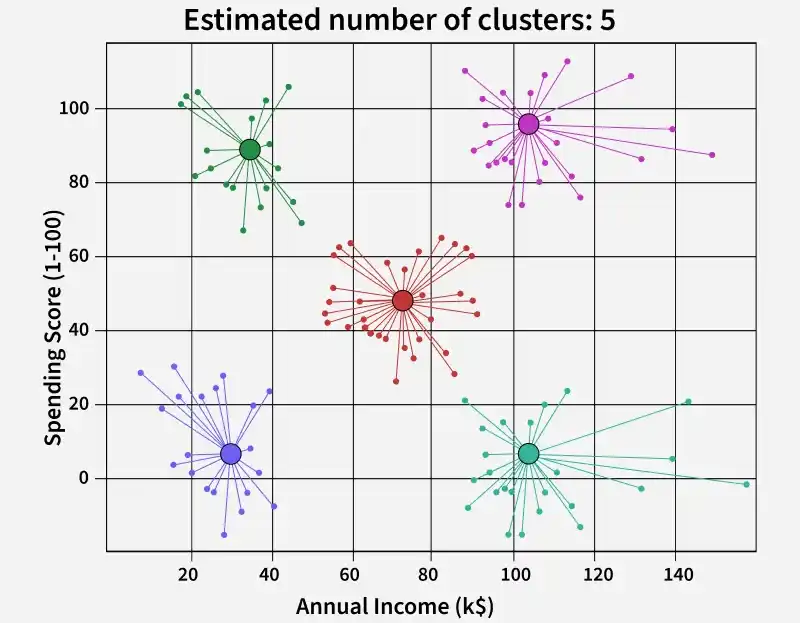
We will create a plot where clustering effect can be visualized.
Output:
Applying Affinity Propagation resulted in 5 distinct and well-separated clusters, clearly segmenting the customers based on their income and spending scores
You can download the complete code from here .
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}