 |
VOOZH | about |
|
VOOZH | about |
Bernoulli Naive Bayes is a subcategory of the Naive Bayes Algorithm. It is typically used when the data is binary and it models the occurrence of features using Bernoulli distribution. It is used for the classification of binary features such as 'Yes' or 'No', '1' or '0', 'True' or 'False' etc. Here it is to be noted that the features are independent of one another.
In Bernoulli Naive Bayes model we assume that each feature is conditionally independent given the class . This means that we can calculate the likelihood of each feature occurring as:
Now we will learn Bernoulli distribution as Bernoulli Naive Bayes works on that.
Bernoulli distribution is used for discrete probability calculation. It either calculates success or failure. Here the random variable is either 1 or 0 whose chance of occurring is either denoted by p or (1-p) respectively. The mathematical formula is given
Now in the above function if we put x=1 then the value of f(x) is p and if we put x=0 then the value of f(x) is 1-p. Here p denotes the success of an event.
To understand how Bernoulli Naive Bayes works, here's a simple binary classification problem.
Message ID | Message Text | Class |
|---|---|---|
M1 | "buy cheap now" | Spam |
M2 | "limited offer buy" | Spam |
M3 | "meet me now" | Not Spam |
M4 | "let's catch up" | Not Spam |
Extract all unique words from the training data:
Vocabulary size
Each message is represented using binary features indicating the presence (1) or absence (0) of a word.
ID | buy | cheap | now | limited | offer | meet | me | let's | catch | up | Class |
|---|---|---|---|---|---|---|---|---|---|---|---|
M1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Spam |
M2 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | Spam |
M3 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | Not Spam |
M4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | Not Spam |
where for both classes (2 documents per class), so the denominator becomes 4.
For Spam class:
For Not Spam class:
The message contains words "buy" and "now, so the feature vector is:
5.1 For Spam:
5.2 For Not Spam:
Since , the message is classified as:
For performing classification using Bernoulli Naive Bayes we have considered an email dataset.
The email dataset comprises of four columns named Unnamed: 0, label, label_num and text. The category of label is either ham or spam. For ham the number assigned is 0 and for spam 1 is assigned. Text comprises the body of the mail. The length of the dataset is 5171.
The dataset can be downloaded from here.
In the code we have imported necessary libraries like pandas, numpy and sklearn. Bernoulli Naive Bayes is a part of sklearn package.
In this code we have performed a quick data analysis that includes reading the data, dropping unnecessary columns, printing shape of data, information about dataset etc.
Output:
(5171, 4) Index(['Unnamed: 0', 'label', 'text', 'label_num'], dtype='object')
In the code since text data is used to train our classifier we convert the text into a matrix comprising numbers using Count Vectorizer so that the model can perform well.
Output:
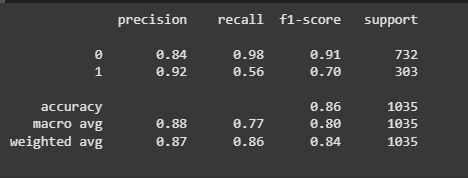
The classification report shows that for class 0 (not spam) precision, recall and F1 score are 0.84, 0.98 and 0.91 respectively. For class 1 (spam) they are 0.92, 0.56 and 0.70. The recall for class 1 drops due to the 13% spam data. The overall accuracy of the model is 86%, which is good.
Bernoulli Naive Bayes is used for spam detection, text classification, Sentiment Analysis and used to determine whether a certain word is present in a document or not.
| Aspect | Gaussian Naive Bayes | Multinomial Naive Bayes | Bernoulli Naive Bayes |
|---|---|---|---|
| Feature Type | Continuous (real-valued features) | Discrete (count data or frequency-based features) | Binary (presence or absence of features) |
| Assumption | Assumes data follows a Gaussian (normal) distribution | Assumes data follows a multinomial distribution | Assumes data follows a Bernoulli (binary) distribution |
| Common Use Case | Suitable for continuous features like height, weight, etc. | Suitable for text classification (word counts) | Suitable for binary classification tasks (e.g., spam detection) |
| Data Representation | Features are treated as continuous variables | Features are treated as discrete counts or frequencies | Features are treated as binary (0 or 1) values |
| Mathematical Model | Uses Gaussian distribution (mean and variance) for each feature | Uses the multinomial distribution for word counts in text classification | Uses Bernoulli distribution (probability of a feature being present) |
| Example | Predicting whether an email is spam based on numeric features | Predicting whether a document is spam based on word counts | Classifying a document as spam or not based on word presence |
Here is the quick comparison between types of Naive Bayes that are Gaussian Naive Bayes, Multinomial Naive Bayes and Bernoulli Naive Bayes.
{kind=link}
{kind=link}