 |
VOOZH | about |
|
VOOZH | about |
Model evaluation is a crucial part of the machine learning process. When it comes to evaluating clustering in machine learning, optimizing the cluster count is a critical component. The Davies-Bouldin Index is a well-known metric to perform the same - it enables one to assess the clustering quality by comparing the average similarity between the pairwise most similar clusters. This article will explore the concepts related to the Davies-Bouldin Index and its implementation in Scikit-Learn.
Clustering is a type of unsupervised machine learning that involves arranging/grouping the most similar data points into a fixed number of clusters. It is suitable for finding any structures or patterns within the data without requiring any prior knowledge about the grouping logic. It is very useful in segmentation tasks and finds a wide variety of applications like image compression, anomaly detection, and customer segmentation.
The Davies-Bouldin Index is a validation metric that is used to evaluate clustering models. It is calculated as the average similarity measure of each cluster with the cluster most similar to it. In this context, similarity is defined as the ratio between inter-cluster and intra-cluster distances. As such, this index ranks well-separated clusters with less dispersion as having a better score.
For a dataset , the Davies-Bouldin Index for k number of clusters can be calculated as
where:
is the intracluster distance within the cluster .
is the intercluster distance between the clusters .
The Davies-Bouldin index is very effective compared to other clustering evaluation metrics because:
The davies_bouldin_score is provided within the sklearn.metrics module of the scikit-learn library. The following syntax is to be followed:
sklearn.metrics.davies_bouldin_score(X, labels)
The Davies-Bouldin Index (DBI) is a metric for evaluating the validity of a clustering solution. It is a relative clustering validity index, meaning that it compares the clustering results to a hypothetical "ideal" clustering. A lower DBI value indicates a better clustering solution.
Below is the Python implementation of DB index using the sklearn library
Scikit-Learn - Scikit-Learn is a popular Python3 library that provides a variety of methods to enable implementation of machine learning techniques like clustering, regression and classification. It provides various model evaluation scores, such as the Davies-Bouldin score, as part of its sklearn.metrics module.
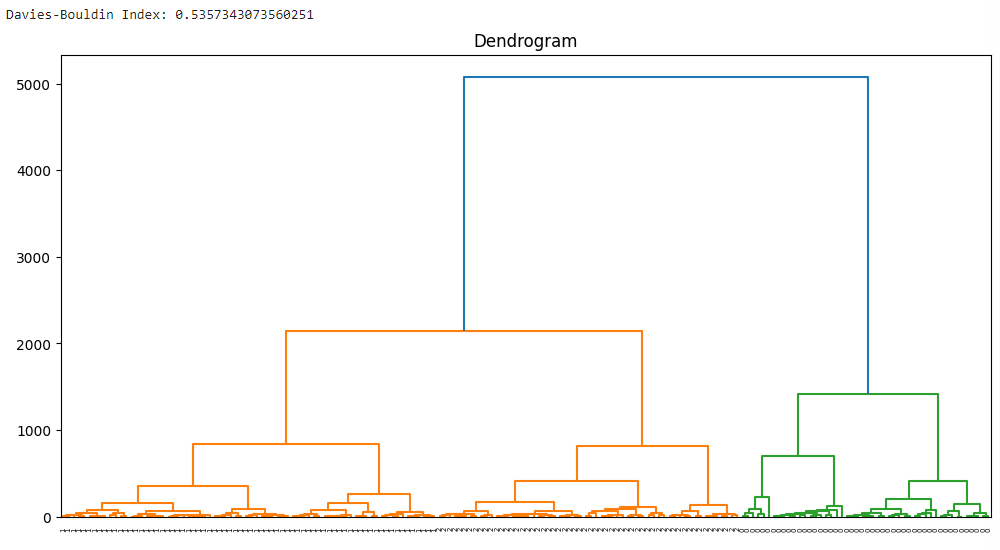
The code performs Agglomerative Hierarchical Clustering (AHC) on the Wine dataset and calculates the Davies-Bouldin Index (DBI) to evaluate the clustering results. It also plots a dendrogram to visualize the hierarchical structure of the data.
Output:
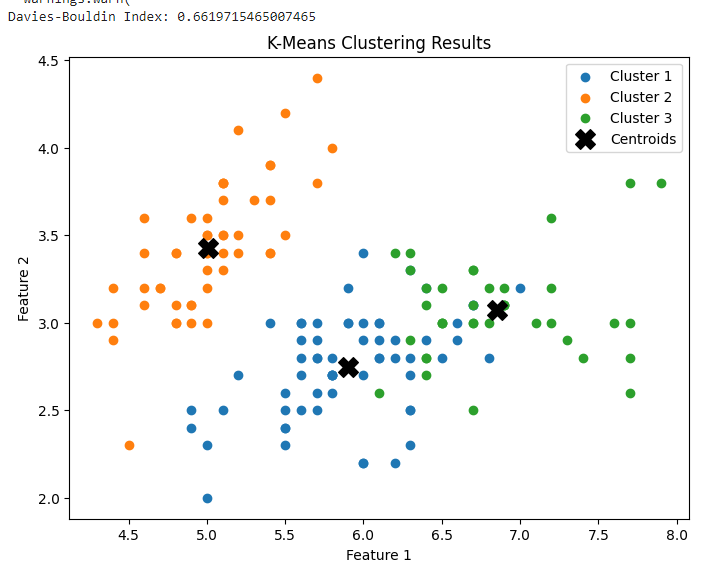
The code performs K-Means clustering on the Iris dataset and calculates the Davies-Bouldin Index (DBI) to evaluate the clustering results. It also plots a scatter plot to visualize the clustering results.
Output:
👁 Screenshot-2023-10-31-164703
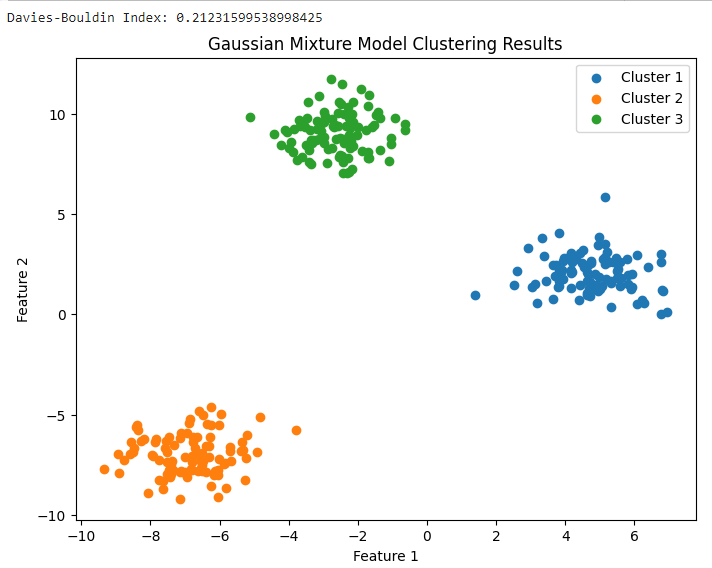
The code performs Gaussian Mixture Model (GMM) clustering on a synthetic dataset generated using scikit-learn's make_blobs function. It also calculates the Davies-Bouldin Index (DBI) to evaluate the clustering results and plots a scatter plot to visualize the clustering results.
Output:
👁 Screenshot-2023-10-31-164716
{kind=link}
{kind=link}
{kind=link}
{kind=link}