Clustering is an unsupervised machine learning technique used to group similar data points together without using labelled data. It helps discover hidden patterns or natural groupings in datasets by placing similar data points into the same cluster.
Discover the natural grouping or structure in unlabelled data without predefined categories.
Data points are assigned to clusters based on similarity or distance measures.
Uses Euclidean distance, cosine similarity or other metrics depending on data type and clustering method.
Hard clustering assigns each data point to exactly one cluster. A data point cannot belong to multiple clusters, making the grouping clear and easy to interpret.
Each data point belongs to only one cluster
No overlap between clusters
Simple and easy to interpret
Example
If customers are divided into two clusters, each customer belongs completely to either Cluster 1 or Cluster 2. A customer cannot belong to both clusters at the same time.
Common Uses
Market segmentation: Businesses group customers with similar buying behaviour to design targeted marketing strategies.
Customer grouping: Companies organize customers into clear categories for better service and analysis.
Document clustering: Documents with similar topics or keywords are grouped together for easier organization.
Limitation
Cannot represent overlapping groups: Hard clustering cannot handle situations where a data point may logically belong to multiple groups.
2. Soft Clustering
Soft clustering allows a data point to belong to multiple clusters with different probabilities. Instead of assigning a strict cluster, it gives a degree of membership to each cluster.
Example
A data point may belong 70% to Cluster 1 and 30% to Cluster 2, indicating that it shares characteristics with both groups.
Use Cases
Overlapping class boundaries: Useful when data points cannot be clearly separated into distinct groups.
Customer personas: Helps represent customers who share traits with multiple behavioral groups.
Medical diagnosis: Patients may show symptoms related to multiple conditions.
Benefits
Captures ambiguity: Represents uncertainty when cluster boundaries are not clear.
Models gradual transitions: Allows smooth transitions between clusters instead of strict separation.
Clustering Methods
1. Centroid based Clustering
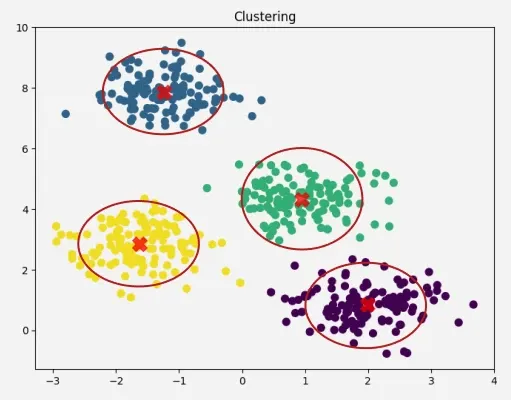
Centroid based clustering groups data points around central points called centroids. Each cluster is represented by a central point (centroid or medoid), and data points are assigned to the nearest center.
K-medoids: Similar to K-means but uses actual data points (medoids) as centers, robust to outliers.
Advantages:
Fast and scalable for large datasets.
Simple to implement and interpret.
Limitations:
Requires choosing number of clusters in advance
Sensitive to initialization and outliers.
Not suitable for non spherical clusters.
2. Density based Clustering
Density based clustering identifies clusters as regions where data points are densely packed together. Points in low density areas are treated as noise.
Algorithms:
DBSCAN: Groups points with sufficient neighbors; labels sparse points as noise.
OPTICS: Extends DBSCAN to handle varying densities.
Advantages:
Handles clusters of varying shapes and sizes.
Does not require cluster count upfront.
Effective in noisy datasets.
Limitations:
Difficult to choose parameters like epsilon and min points.
Less effective for varying density clusters (except OPTICS).
3. Connectivity based Clustering
Connectivity based or Hierarchical clustering builds clusters by gradually merging or splitting groups of data points. It creates a tree like structure called a dendrogram that shows relationships between clusters.
Approaches:
Agglomerative: Starts with each point as a cluster and merges them step by step.
Divisive: Starts with one cluster and splits it into smaller clusters.
Advantages:
Provides a full hierarchy, easy to visualize
No need to specify number of clusters upfront
Limitations
Computationally intensive for large datasets
Merging/splitting decisions are irreversible
Choosing parameters can be difficult
4. Distribution-based Clustering
Distribution based clustering assumes that data points come from a mixture of probability distributions. Each cluster is modelled as a statistical distribution.
Algorithm:
Gaussian Mixture Model (GMM): Fits data as a weighted mixture of Gaussian distributions, assigns data points based on likelihood
Advantages:
Works well for clusters that are not perfectly circular.
Provides probabilistic memberships
Suitable for overlapping clusters
Limitations:
Requires specifying number of components
Computationally more expensive
Sensitive to initialization
5. Fuzzy Clustering
Fuzzy clustering allows data points to belong to multiple clusters with different degrees of membership. It is useful when cluster boundaries are not clear.
Algorithm:
Fuzzy C-Means: Similar to K-means but with fuzzy memberships updated iteratively
Advantages:
Models data ambiguity explicitly
Useful for complex or imprecise data
Limitations:
Choosing fuzziness parameter can be tricky
Slightly higher computational cost
Applications
Customer Segmentation: Group customers based on behaviour or demographics.
Anomaly Detection: Detect unusual activities in finance, security or sensor data.
Image Segmentation: Divide images into meaningful regions for computer vision tasks.
Recommendation Systems: Group similar users or items for personalized suggestions.

{kind=link}
{kind=link}