A decision tree is a popular supervised machine learning algorithm used for both classification and regression tasks. It works with categorical as well as continuous output variables and is widely used due to its simplicity, interpretability and strong performance on structured data.
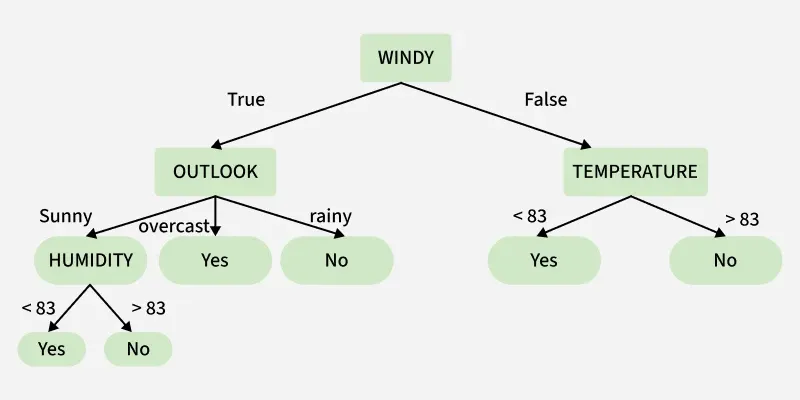
In the above figure, a decision tree is a flowchart-like structure with a root node (WINDY), internal nodes (OUTLOOK, TEMPERATURE) for attribute tests and leaf nodes for final decisions. The branches show the possible outcomes of each test. A Decision Tree follows a tree-like structure where:
Nodes represent decisions or feature tests
Branches represent outcomes of those decisions
Leaf nodes represent final predictions or class labels
The tree is constructed by recursively splitting the dataset based on the feature that provides the maximum information gain or minimum impurity.
How Decision Trees Work
Decision Trees work by selecting the best attribute at each step to split the data. This selection is based on statistical metrics that measure data impurity or uncertainty.
Start with the full dataset as the root node.
Select the best feature using a splitting criterion.
Split the dataset into subsets.
Repeat the process recursively until stopping conditions are met.
Assign class labels at leaf nodes.
Splitting Criteria in Decision Trees
Decision Trees select the best attributes for splits using metrics like Gini Index, Entropy and Information Gain helping decide the root and internal nodes. Entropy measures dataset impurity, guiding the tree to choose splits that reduce uncertainty.
1. Gini Index
Measures the probability of misclassifying a randomly chosen element lower values are better.
where is probability of class in a node.
2. Entropy
Quantifies the uncertainty or impurity in a dataset higher entropy means more disorder.
where
: possible value of a variable
: probability of
3. Information Gain
Measures the reduction in entropy achieved by splitting data on an attribute higher gain is preferred.
: Entropy before split.
: Entropy of subset after split.
: Reduction in entropy from splitting on A.
Step By Step Implementation
Here we implement Decision Tree classifiers on the Balance Scale dataset, evaluate their performance and visualize the resulting trees.
import scikit learn for Decision Tree implementation
Import metrics for evaluating model performance
Step 2: Import Dataset
Load the dataset from the UCI repository.
Display dataset length, shape and first few rows.
Returns the dataset for further processing.
Step 3: Split Dataset into Features and Labels
Separate input features (X) and target labels (Y).
Split data into training and testing sets.
Return both the complete dataset and split sets for modeling.
Step 4: Train Decision Tree Using Gini Index
Initialize DecisionTreeClassifier with gini criterion.
Set max_depth and min_samples_leaf to control tree complexity.
Fit the model on training data and return the trained classifier.
Step 5: Train Decision Tree Using Entropy
Initialize classifier with entropy criterion.
Same depth and leaf settings to compare with Gini.
Fit the model on training data and return the trained classifier.
Step 6: Make Predictions
Use the trained classifier to predict target labels for the test set.
Step 7: Evaluate Model Accuracy
Calculate and display the confusion matrix.
Compute accuracy score.
Show detailed classification report including precision, recall and F1-score.
Step 8: Visualize the Decision Tree
Plot the trained decision tree using matplotlib.
Include feature names and class names for better readability.
Step 9: Train, Predict and Evaluate Models
Load and split the dataset into training and testing sets.
Train classifiers using Gini and Entropy criteria.
Make predictions on the test set and evaluate accuracy using confusion matrix, accuracy score and classification report.
Output:
The Decision Tree trained using Gini and Entropy achieves around 73% and 71% accuracy respectively, showing similar performance. Both models classify L and R classes reasonably well, but fail to correctly predict the B class, likely due to class imbalance.
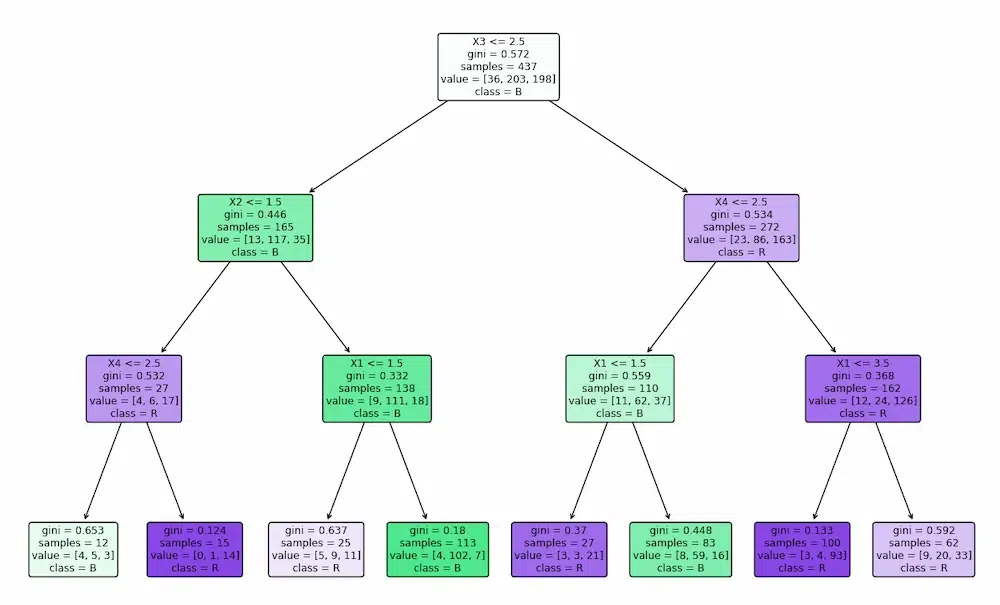
Step 10: Visualize Decision Trees
Plot both Gini and Entropy trained decision trees using matplotlib.
Gini Index Tree: The tree splits features based on minimizing the Gini impurity focusing on how often a randomly chosen element would be incorrectly classified. It aims for pure nodes with minimal class mixing.
Entropy Tree: The tree splits features based on information gain (entropy reduction), selecting splits that maximize the reduction in uncertainty about the class labels. It tends to create balanced splits that reduce overall disorder.

{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}