 |
VOOZH | about |
|
VOOZH | about |
Dirichlet Process Mixture Models (DPMMs) is a flexible clustering method that can automatically decide the number of clusters based on the data. Unlike traditional methods like K-means which require you to specify the number of clusters. It offers a probabilistic and nonparametric approach to clustering which allows the model to figure out number of groups on its own based complexity of the data.
To understand DPMMs it's important to understand two key concepts:
The Beta distribution models probabilities for two possible outcomes such as success or failure. It is defined by two parameters α and β that shape the distribution. The probability density function (PDF) is given by:
Where B(α, β) is the beta function.
The Dirichlet distribution is a generalization of the Beta distribution for multiple outcomes. It represents the probabilities of different categories like rolling a dice with unknown probabilities for each side. The PDF of the Dirichlet distribution is:
Where:
A Dirichlet Process is a stochastic process that generates probability distributions over infinite categories. It enables clustering without specifying the number of clusters in advance. The Dirichlet Process is defined as:
Where:
The stick-breaking process is a method to generate probabilities from a Dirichlet Process. The concept is shown in the image below:
Steps
Mathematically this can be expressed as
p1 = β(1,α)
p2 = β(1, α) ∗(1 - p1)
p3 = β(1, α) ∗(1 - p1 -p2)
For each categories sample we also sample μ from our base distribution. This becomes our cluster parameters.
DPMM is an extension of Gaussian Mixture Models where the number of clusters is not fixed. It uses the Dirichlet Process as a prior for the mixture components.
1. Initialize: Assign random clusters to data points.
2. Iterate for Each Data Point:
3. Update: Assign the point to whichever option has the higher probability.
4. Repeat: Continue until the cluster assignments stop changing.
1. Assigning to an existing cluster k
2. Assigning to a new cluster
Where:
DPMM is an extension of Gaussian Mixture Models where the number of clusters is not fixed. It uses the Dirichlet Process as a prior for the mixture components.
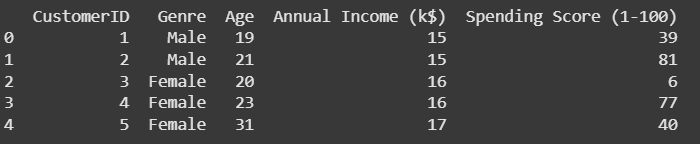
Now let us implement DPMM process in scikit learn and we'll use the Mall Customers Segmentation Data. Let's understand this step-by-step:
In this step we will import all the necessary libraries. This dataset contains customer information, including age, income and spending score. You can download the dataset from here.
Output:
In this step we select features that are likely to influence customer clusters.
We will use PCA algorithm to reduces the data's dimensions to 2 for easy visualization.
The model can automatically deactivate unnecessary components up to a specified maximum number of clusters (n_components).
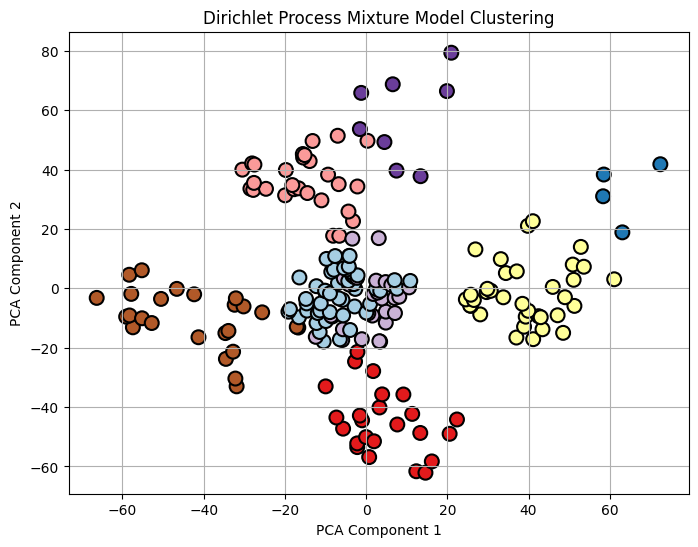
Clusters are visualized with different colors making patterns easier to interpret.
Output:
The clustering of mall customers using DPMM highlights distinct groups where average customers in the center and extreme spenders on the edges. Overlapping clusters suggest some customers share similar behaviors.
You can download the complete code from here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}