 |
VOOZH | about |
|
VOOZH | about |
Fake news on different platforms is spreading widely and is a matter of serious concern, as it causes social wars and permanent breakage of the bonds established among people. A lot of research is already going on focused on the classification of fake news.
Here we will try to solve this issue with the help of machine learning in Python.
Before starting the code, download the dataset by clicking the link.
The libraries used are :
Let's import the downloaded dataset.
Output :
The shape of the dataset can be found by the below code.
Output:
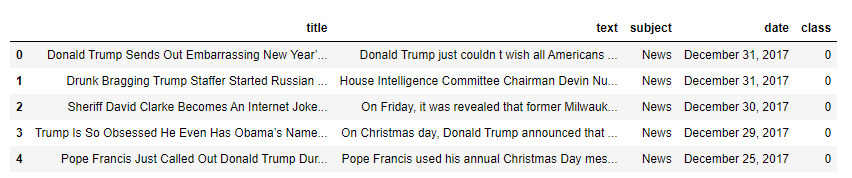
(44919, 5)As the title, subject and date column will not going to be helpful in identification of the news. So, we can drop these column.
Now, we have to check if there is any null value (we will drop those rows)
Output:
text 0
class 0
So there is no null value.
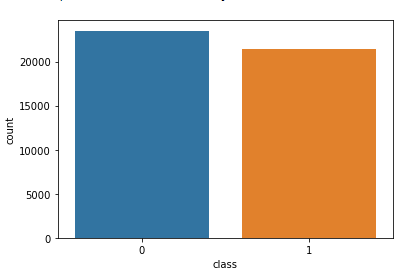
Now we have to shuffle the dataset to prevent the model to get bias. After that we will reset the index and then drop it. Because index column is not useful to us.
Now Let's explore the unique values in the each category using below code.
Output:
Firstly we will remove all the stopwords, punctuations and any irrelevant spaces from the text. For that NLTK Library is required and some of it's module need to be downloaded. So, for that run the below code.
Once we have all the required modules, we can create a function name preprocess text. This function will preprocess all the data given as input.
To implement the function in all the news in the text column, run the below command.
This command will take some time (as the dataset taken is very large).
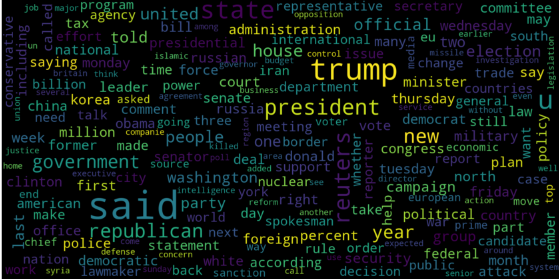
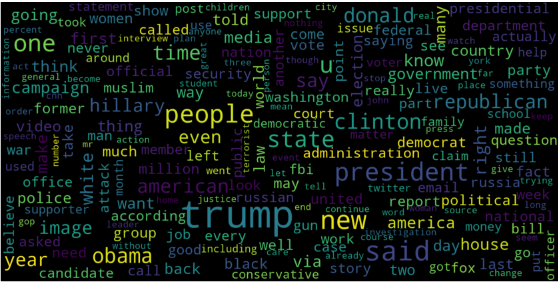
Let's visualize the WordCloud for fake and real news separately.
Output :
Output :
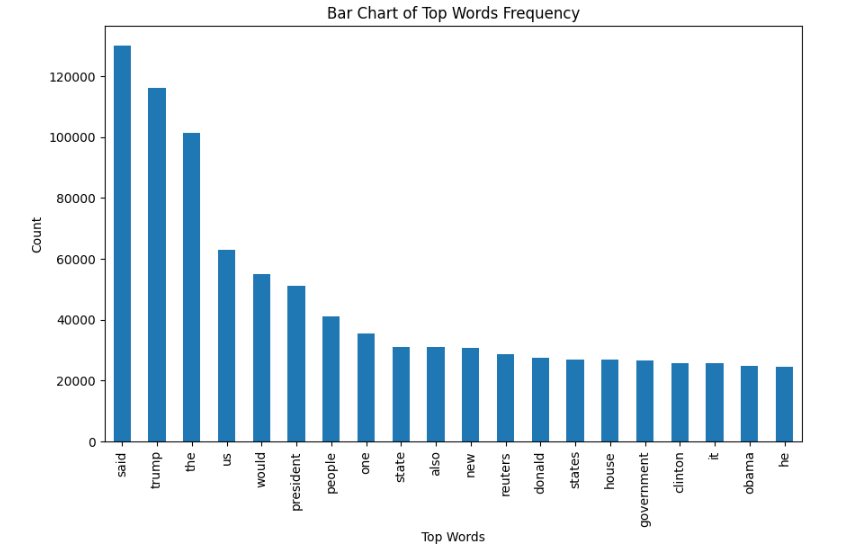
Now, Let's plot the bargraph of the top 20 most frequent words.
Output :
Before converting the data into vectors, split it into train and test.
Now we can convert the training data into vectors using TfidfVectorizer.
Now, the dataset is ready to train the model.
For training we will use Logistic Regression and evaluate the prediction accuracy using accuracy_score.
Output :
0.993766511324171
0.9893143365983972
Let's train with Decision Tree Classifier.
Output :
0.9999703167205913
0.9951914514692787
The confusion matrix for Decision Tree Classifier can be implemented with the code below.
Output :
Get the complete notebook link here:
Colab Link : click here.
Dataset Link : click here.
Decision Tree Classifier and Logistic regression are performing well.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}