 |
VOOZH | about |
|
VOOZH | about |
Handwritten digit recognition is a classic problem in machine learning and computer vision. It involves recognizing handwritten digits (0-9) from images or scanned documents. This task is widely used as a benchmark for evaluating machine learning models especially neural networks due to its simplicity and real-world applications such as postal code recognition and bank check processing. In this article we will implement Handwritten Digit Recognition using Neural Network.
Let’s implement the solution step-by-step using Python and TensorFlow/Keras.
Before starting, we need to import the necessary libraries for data manipulation, visualization, and model building. We will use numpy, matplotlib, scikit learn and tenserflow.
We will load the dataset and inspect its structure to understand the features and labels. You can download this dataset from here.
label) indicates the digit (0-9) and the remaining columns represent pixel values of the image. X (pixel values) and y (labels). X has 42,000 samples with 784 features (28x28 pixels) and y has 42,000 labels.Shape of train_data: (42000, 785)
Shape of X after separating features: (42000, 784)
Raw data often needs cleaning and formatting before it can be fed into a neural network. Let’s preprocess the data to make it ready for training.
X is in the correct format (Pandas DataFrame).0.[0, 1] by dividing them by 255.0. This helps the model learn faster.Output
Shape of X after reshaping: (42000, 28, 28, 1)
Neural networks work best when labels are in a specific format called "one-hot encoding." Let’s convert our labels into this format.
Output:
Shape of y after one-hot encoding: (42000, 10)
To evaluate our model effectively we need to split the data into a training set and a validation set. Here we will use 80% data for training rest for testing.
Output:
X_train shape: (33600, 28, 28, 1)
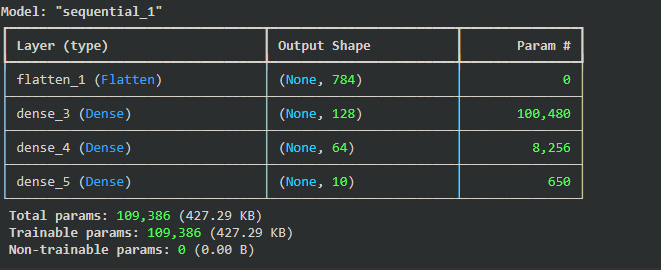
Now let’s define the architecture of our neural network. We define a simple feedforward neural network with three layers:
Flatten layer converts the 28x28 image into a single vector of length 784.Output:
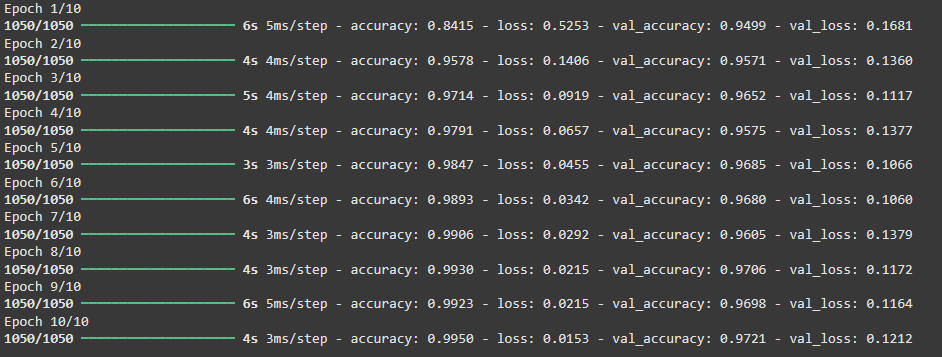
With the model defined it’s time to train it on the training data. The model trains for 10 iterations (epochs) over the entire training dataset. During training it processes the data in batches of 32 samples for efficiency.
Output:
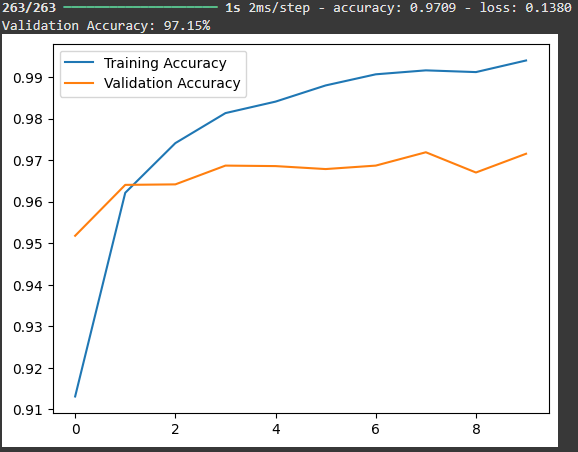
Once training is complete we evaluate the model’s performance on the validation set and plot the training and validation accuracy to see how well the model learned over time. This helps us identify issues like overfitting.
Output:
The blue line represents the training accuracy which consistently increases over the training steps while the orange line represents the validation accuracy which fluctuates slightly but shows a positive trend. By the end of the training the model achieves a training accuracy of around 96.81% and a validation accuracy of 97.13% indicating the model performs well on both training and validation data suggesting good generalization capability.
Let’s use the trained model to make predictions on new data. We load the test data preprocess it similarly to the training data and feed it into the model to get predictions. You can download the test dataset from here.
Output:
Our model is working fine making right predictions.
By using neural network architecture we were able to train the model on a dataset of 42,000 handwritten digits achieving impressive accuracy. The model successfully generalized making it capable of recognizing unseen digits effectively. This process showcases the potential of machine learning algorithms in solving real-world problems involving image recognition.
Get Source code from here: click here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}