 |
VOOZH | about |
|
VOOZH | about |
Predicting house prices is a key challenge in the real estate industry, helping buyers, sellers and investors make informed decisions. By using machine learning algorithms, we can estimate the price of a house based on various features such as location, size, number of bedrooms and other relevant factors.
We will use the House Price Prediction Dataset, which can be downloaded from the provided link. The dataset contains 13 key features:
In the first step we load the libraries which is needed for Prediction:
You can download full dataset from here
Output:
👁 ImageAs we have imported the data. So shape method will show us the dimension of the dataset.
Output:
(2919,13)
Here we categorize the features based on their data types (integer, float, or object) and count the number of features in each category.
Output:
Categorical variables: 4
Integer variables: 6
Float variables: 3
Exploratory Data Analysis involves examining the dataset in depth to uncover patterns, detect anomalies and understand the underlying structure. Before drawing any conclusions, it’s important to analyze all variables carefully.
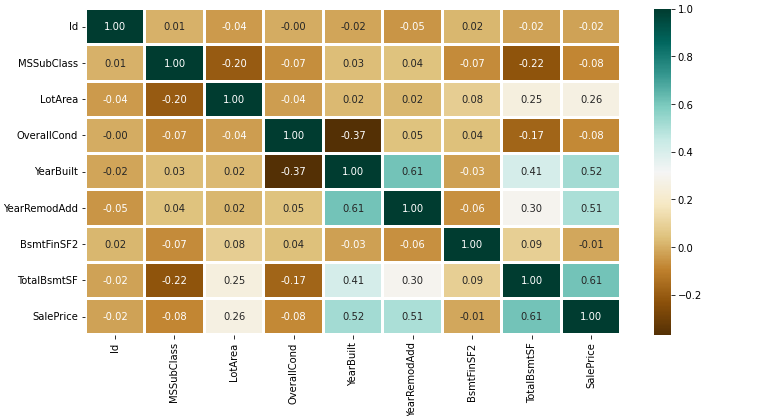
Here we will create a heatmap using the Seaborn library to visualize correlations between features.
Output:
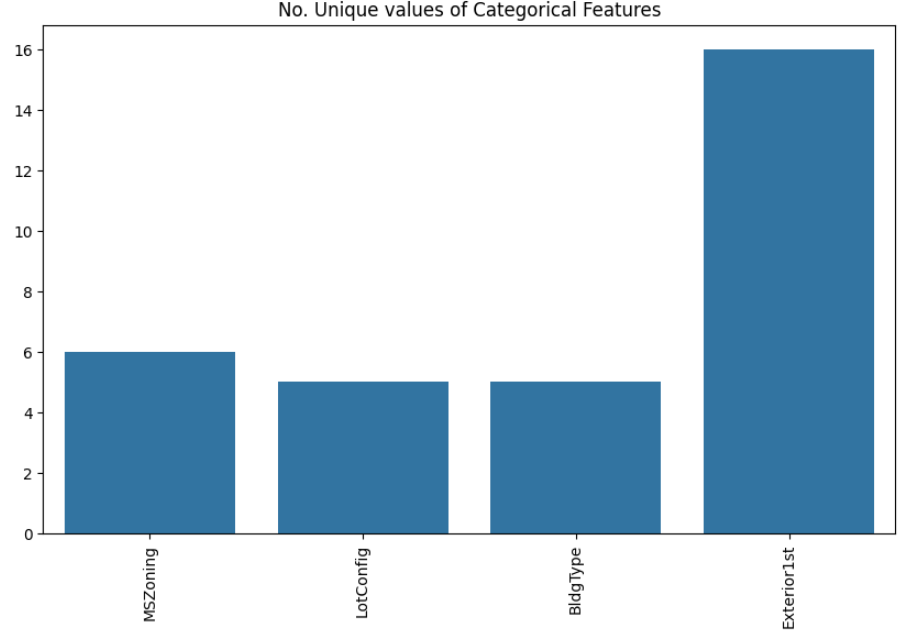
To examine the categorical features, we will create a bar plot to visualize their distributions
Output:
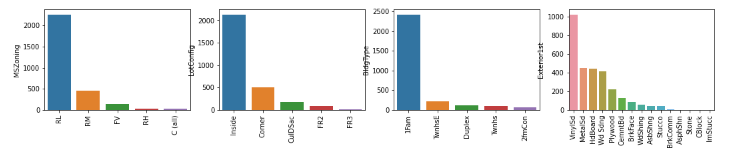
The plot shows that Exterior1st has around 16 unique categories and other features have around 6 unique categories. To findout the actual count of each category we can plot the bargraph of each four features separately.
Output:
Data Cleaning is the way to improvise the data or remove incorrect, corrupted or irrelevant data. As in our dataset there are some columns that are not important and irrelevant for the model training. So we can drop that column before training. There are 2 approaches to dealing with empty/null values
As Id Column will not be participating in any prediction. So we can Drop it.
Replacing SalePrice empty values with their mean values to make the data distribution symmetric.
Drop records with null values (as the empty records are very less).
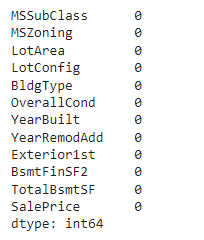
Checking features which have null values in the new dataframe (if there are still any).
Output:
One hot Encoding is the best way to convert categorical data into binary vectors. This maps the values to integer values. By using OneHotEncoder, we can easily convert object data into int. So for that firstly we have to collect all the features which have the object datatype. To do so, we will make a loop.
Output:
Then once we have a list of all the features. We can apply OneHotEncoding to the whole list.
X and Y splitting (i.e. Y is the SalePrice column and the rest of the other columns are X)
As we have to train the model to determine the continuous values, so we will be using these regression models.
And To calculate loss we will be using the mean_absolute_percentage_error module. It can easily be imported by using sklearn library. The formula for Mean Absolute Error is:
Support vector Machine is a supervised machine learning algorithm primarily used for classification tasks though it can also be used for regression. It works by finding the hyperplane that best divides a dataset into classes. The goal is to maximize the margin between the data points and the hyperplane.
Output :
0.1870512931870423
Random Forest is an ensemble learning algorithm used for both classification and regression tasks. It constructs multiple decision trees during training where each tree in the forest is built on a random subset of the data and features, ensuring diversity in the model. The final output is determined by averaging the outputs of individual trees (for regression) or by majority voting (for classification).
Output :
0.18602695581046166
Linear Regression is a statistical method used for modeling the relationship between a dependent variable and one or more independent variables. The goal is to find the line that best fits the data. This is done by minimizing the sum of the squared differences between the observed and predicted values. Linear regression assumes that the relationship between variables is linear.
Output :
0.1874168384159986
Clearly SVM model is giving better accuracy as the mean absolute error is the least among all the other regressor models i.e. 0.18 approx. To get much better results ensemble learning techniques like Bagging and Boosting can also be used.
You can download full code from here
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}