Topic modelling is an NLP technique used to find hidden topics in large text collections. Latent Dirichlet Allocation (LDA) is a popular topic modeling method that groups documents based on similar word patterns without using labelled data.
LDA is an unsupervised probabilistic model.
Each document is represented as a mixture of topics.
Each topic is represented as a distribution of words.
Components of Latent Dirichlet Allocation(LDA)
Probabilistic Generative Model
LDA assumes that each document is generated using a two-step random process:
For each document, sample a distribution over topics (using a Dirichlet prior).
For each word in the document, sample a topic from the document’s topic distribution, then sample a word from the selected topic’s word distribution.
Role of Dirichlet Distributions
The model uses Dirichlet distributions in two places:
To model the diversity of topic proportions for each document (parameter α).
To model the diversity of word proportions for each topic (parameter β).
LDA as a Mixture Model
Each document is viewed as a random mixture of topics and each topic as a mixture over words. For example, an article about sports might be a combination of topics like “teams,” “games,” and “scores.” LDA discovers these topics based on patterns in word usage across the corpus.
Bayesian Inference in LDA
LDA uses Bayesian inference to "reverse engineer" the hidden topics from the observed words in documents. Techniques like Gibbs sampling or variational Bayes are used to estimate the latent variables:
The topic proportions in each document.
The word probabilities in each topic.
Key Model Parameters
: Controls per-document topic diversity (high α means documents have many topics).
: Controls per-topic word diversity (high β means topics use many different words).
Step-by-Step Implementation
Let's see the implementation of LDA topic modeling pipeline,
Step 1: Install and Import libraries
We install and import the required libraries,
pandas: Loads, manipulates and inspects tabular data.
numpy: Enables efficient numerical computations; sometimes useful for arrays.
string: Helps remove punctuation during text cleaning.
spacy: Processes text (tokenizes, tags, lemmatizes) for NLP tasks.
nltk: Supplies English stopwords and other language tools.
gensim: Performs topic modeling and creates bag-of-words matrices.
pd.read_csv('/content/mock_yelp.csv'): Loads Yelp-style reviews from a CSV into a pandas DataFrame.
print(len(yelp_review)), groupby('business_id'): Quickly checks how many reviews, unique businesses and users are present.
Output:
number of reviews:10 Unique Business:5 Unique User:5
Step 3: Preprocess Text
3.1 Clean text: clean_text(text): Removes punctuation and digits, lowercases text and discards short/non-informative words. Ensures input text is standardized for modeling.
3.2 Remove Stopwards:
Calls to nltk.download('stopwords') and stopwords.words('english'): Retrieves an extensive list of English stopwords.
remove_stopwords(text): Filters these stopwords from reviews so only content-rich words remain.
3.3 Lemmatization(nouns, adjectives):
spacy.cli.download("en_core_web_md"): Downloads spaCy’s medium English model with vocabulary and grammatical info.
en_core_web_md.load(disable=['parser', 'ner']): Loads the model for fast lemmatization, ignoring other NLP features to speed up code.
lemmatization(texts, allowed_postags=['NOUN', 'ADJ']): Converts all reviews into lists of base-form words (lemmas), only keeping nouns and adjectives, which are most useful for discovering themes.
Step 4: Create Document-Term Matrix
We create the Document-Term Matrix,
corpora.Dictionary(tokenized_reviews): Creates an ID-to-word mapping from tokenized reviews.
[dictionary.doc2bow(rev) for rev in tokenized_reviews]: Builds a bag-of-words matrix needed for LDA input.
Step 5: Fit LDA Model
We prepare the LDA Model,
Instantiates LdaModel from gensim using the corpus and dictionary.
Parameters like num_topics, passes and iterations control how many topics to find and how thoroughly to search for them.
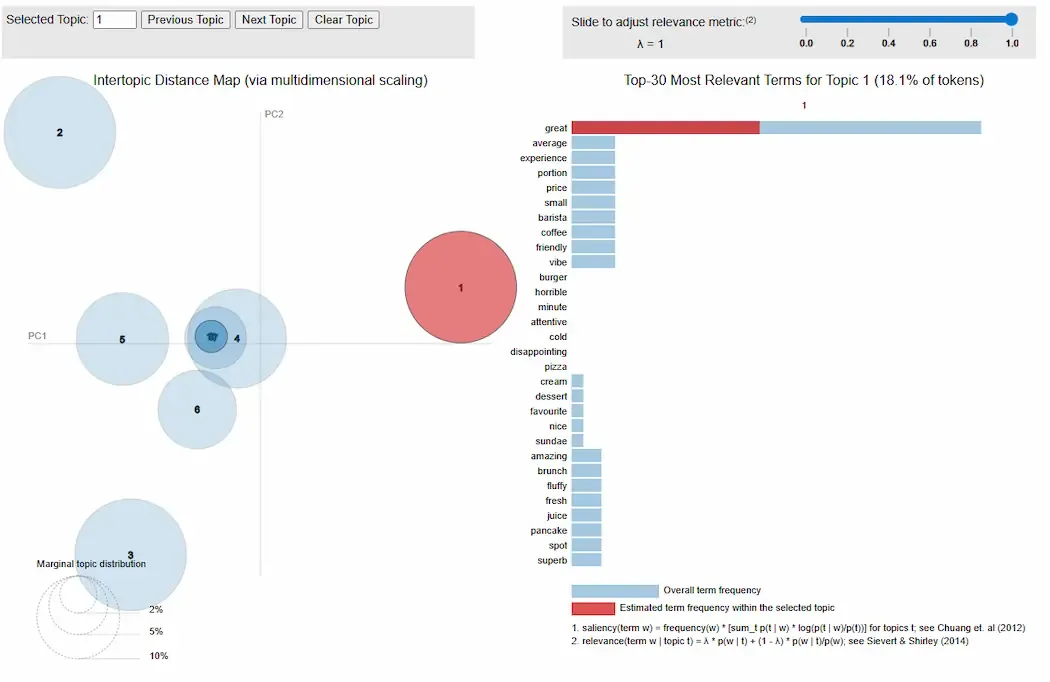
print(lda_model.print_topics()): Outputs the top words and their weights for each detected topic.

{kind=link}
{kind=link}
{kind=link}