 |
VOOZH | about |
|
VOOZH | about |
In the era of Machine learning and Data science, various algorithms and techniques are used to handle large datasets for solving real-world problems effectively. Like various machine learning models, one revolutionary innovation is the LightGBM model which utilizes a high-performance gradient boosting framework. With the efficiency of the LightGBM model, we can add Histogram-based learning which can be a powerful optimization technique that significantly accelerates the training process and enhances overall model performance. In this article, we will implement a histogram-learning-based LightGBM model and check its performance.
Histogram-based learning is a powerful optimization technique used in various supervised machine learning tasks like classification and regression. This technique significantly accelerates the training process and enhances model performance when we are dealing with large datasets. At its core, Histogram-Based Learning transforms the traditional process of decision tree construction during the model training process. Instead of considering every possible split point for each feature, it organizes and bins the feature values into histograms which allows more efficient computations and optimizations. Some key concepts of it are discussed below:
Step 1 - Initialization of hyperparameters, variables and histograms: Hyperparameters are used to configure the behavior of the model in LightGBM's histogram-based learning technique. The data distribution information is stored in variables, and the discretization of continuous features for effective gradient computation—which speeds up training and uses less memory—is accomplished by histograms
Step 2 - Using LightGBM's histogram-based learning, the training loop quickly builds new decision trees by identifying optimal split points using histograms and iteratively computing gradients (pseudo-residuals) for each data point. This approach preserves model accuracy while speeding up the tree-building process.
Step 3 - The model is updated with the new decision trees at each iteration: Without starting from zero when rebuilding the entire tree ensemble, LightGBM's histogram-based learning approach allows the model to progressively enhance its predictive capability by adding the freshly constructed decision trees to the model incrementally at each iteration. Better training results and faster convergence are made possible by this effective updating procedure.
Step 4 - After training, predictions are made for new data points using the ensemble of tree: LightGBM uses the ensemble of trees to forecast fresh data points after training. Every tree produces a forecast, and the ultimate prediction is obtained by adding together the predictions from each tree, frequently using a voting system for classification or a weighted total for regression.
For all gradient boosting type algorithms like LightGBM, histogram-based learning is an integral part during training process. The algorithm starts by creating histograms for each feature which efficiently performs binning and summarizes the data distribution. During tree construction phase, gradients are calculated using these histograms by accelerating the process. Now to enable this special technique, we need to specify some special parameter:
LightGBM can utilize histogram-based learning which is nothing but a technique to streamline the process of decision tree construction during the training phase. Tradition gradient boosting algorithms used to partition data into continuous intervals (bins) to build decision trees where LightGBM directly constructs histograms for each features present in dataset. This technique can provide various advantages which are discussed below:
So, employing histogram-based learning in LightGBM can be effective for various real-world problems like Detection based(fraud, disease etc.), prediction based(click-through rate etc.) and also in recommendation systems.
To implement LightGBM model we need to have 'lightgbm' module installed in our runtime.
!pip install lightgbmAlso to utilize histogram-based learning we need latest version of it.
!pip install --upgrade lightgbmNow we will import all required Python libraries like NumPy, Seaborn, Pandas, SKlearn, Matplotlib etc.
For this implementation, we will load Wine dataset of SKlearn which has total 13 features and one target variable with three classes. Then we will split it to training and testing sets in 80:20 ratio. After that, an important task is to made LightGBM dataset on the basis of this Wine dataset. Unlike other models, LightGBM has its own special dataset format(very much different from NumPy arrays or Pandas Data Frames) for its optimized internal processing.
EDA is very crucial task before model implementation as this provides us deeper insights into the dataset.
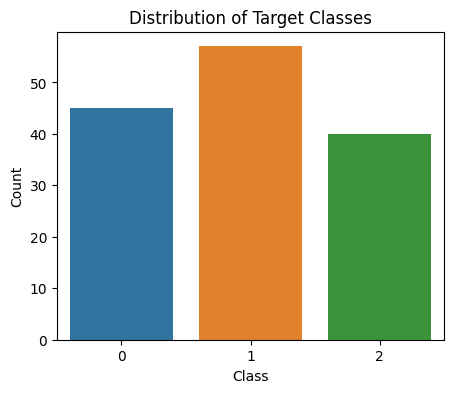
Target Classes distribution
Output:
This EDA helps us to see how the classes of target variable is distributed. Here, three target classes are class_0, class_1, class_2. The np.bincount function is used in this code to determine the number of samples in each class (0 and 1) within the training data (y_train). Then, using Matplotlib and Seaborn, a bar plot is produced, with the plot title describing the distribution of the target classes, and the x-axis representing the unique class labels, the y-axis representing the count of samples. This graphic sheds light on the training dataset's balance or class distribution.
Output:
With the help of the Pandas DataFrame method corr(), this code determines the correlation matrix of the features in the training set (X_train). The correlation matrix is then depicted in a heatmap using Seaborn and Matplotlib. It is simpler to recognize links between features when using the heatmap, which shows pairwise correlations between features. The degree and direction of the correlation are represented by the color intensity.
Now we will trained the model with histogram-based training progress. To enable histogram-based learning we need to define various hyper-parameters(more specifically boosting_type, force_row_wise, histogram_pool_size) which are discussed below:
Histogram-based learning needs a upgraded version of LightGBM model as discussed previously so it is suggested to look into the official documentation.
Output:
[LightGBM] [Info] Total Bins 509
[LightGBM] [Info] Number of data points in the train set: 142, number of used features: 13
[LightGBM] [Info] Start training from score -1.149165
[LightGBM] [Info] Start training from score -0.912776
[LightGBM] [Info] Start training from score -1.266948
Now we will evaluate our model on the basis of various model metrics like accuracy, F1-score.
Output:
Accuracy: 1.00
F1-Score: 1.00
This code first makes predictions (y_pred) by selecting the class with the highest probability for each sample using np.argmax. Then, it evaluates the model's accuracy and F1-score, averaging the F1-scores across all classes using the 'weighted' averaging strategy. The printed metrics provide a summary of the model's classification performance, including accuracy and F1-score.
Output:
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 14
1 1.00 1.00 1.00 14
2 1.00 1.00 1.00 8
accuracy 1.00 36
macro avg 1.00 1.00 1.00 36
weighted avg 1.00 1.00 1.00 36
The results of our research using LightGBM and histogram-based learning are very impressive. Our multiclass classification task-designed model worked remarkably well, obtaining a perfect accuracy of 100%. A crucial parameter for assessing model performance, the F1-score, also hit an astounding 100%. These outcomes underline LightGBM's outstanding skills to handle difficult multiclass classification tasks.Our model's performance can be credited to LightGBM's creative histogram-based learning methodology. This method improves the model's effectiveness and efficiency, allowing it to perform well even in situations where more conventional techniques could falter. The model can interpret and utilize the distribution of data more effectively using histogram-based learning, which improves classification accuracy and F1 scores.
{kind=link}
{kind=link}
.png){kind=link}