Gradient Descent is an optimization algorithm used to find optimal model parameters by minimizing the loss through iterative updates in the direction of the steepest descent.
Uses gradients of the loss function to guide updates
Iterative process that improves model performance over time
Has three main variants: Batch, Stochastic (SGD), and Mini-Batch Gradient Descent
Each variant differs in speed, stability, and convergence behavior
Working of Mini-Batch Gradient Descent
Mini-batch gradient descent updates model parameters using small data subsets, balancing the speed of SGD and the stability of batch gradient descent for efficient and stable training.
Updates parameters using small batches instead of full dataset or single samples
Faster and more efficient due to parallel processing on GPUs/TPUs
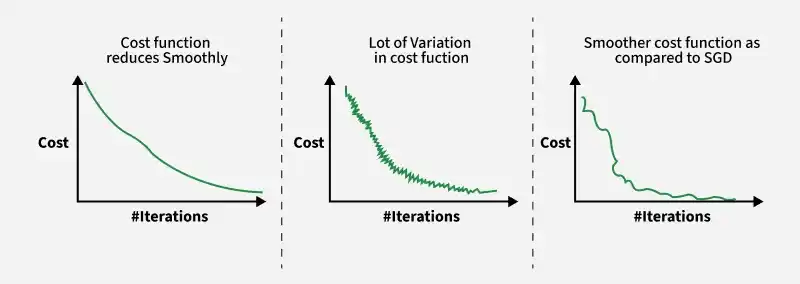
Converges faster with more frequent updates than batch gradient descent
Produces smoother convergence compared to stochastic updates
Introduces slight randomness, helping avoid local minima
Memory efficient as it does not require loading the entire dataset
Algorithm:
Let:
= model parameters
max_iters = number of epochs
= learning rate
For itr=1,2,3,…,max_iters:
Shuffle the training data. It is optional but often done for better randomness in mini-batch selection.
Split the dataset into mini-batches of size .
For each mini-batch (, ):
1. Forward Pass on the batch X_mini:
Make predictions on the mini-batch
Compute error in predictions with the current values of the parameters
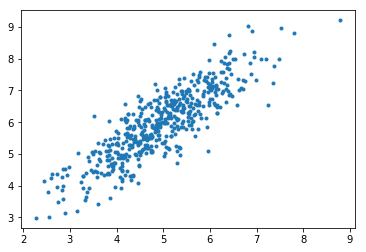
Here, we generate 8000 two-dimensional data points sampled from a multivariate normal distribution:
The data is centered at the point (5.0, 6.0).
The cov matrix defines the variance and correlation between the features. A value of 0.95 indicates a strong positive correlation between the two features.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}