 |
VOOZH | about |
|
VOOZH | about |
As we are approaching modernity, the trend of paying online is increasing tremendously. It is very beneficial for the buyer to pay online as it saves time, and solves the problem of free money. Also, we do not need to carry cash with us. But we all know that Good thing are accompanied by bad things.
The online payment method leads to fraud that can happen using any payment app. That is why Online Payment Fraud Detection is very important.
Here we will try to solve this issue with the help of machine learning in Python.
The dataset we will be using have these columns -
| Feature | Description |
| step | tells about the unit of time |
| type | type of transaction done |
| amount | the total amount of transaction |
| nameOrg | account that starts the transaction |
| oldbalanceOrg | Balance of the account of sender before transaction |
| newbalanceOrg | Balance of the account of sender after transaction |
| nameDest | account that receives the transaction |
| oldbalanceDest | Balance of the account of receiver before transaction |
| newbalanceDest | Balance of the account of receiver after transaction |
| isFraud | The value to be predicted i.e. 0 or 1 |
The libraries used are :
The dataset includes the features like type of payment, Old balance , amount paid, name of the destination, etc. You can download dataset from here.
Output :
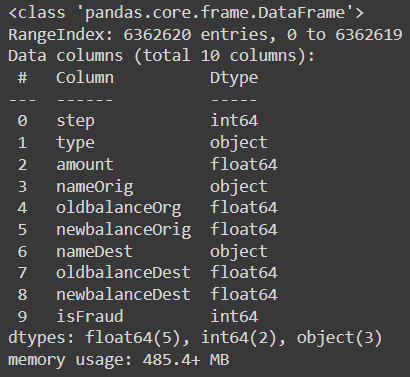
To print the information of the data we can use data.info() command.
Output :
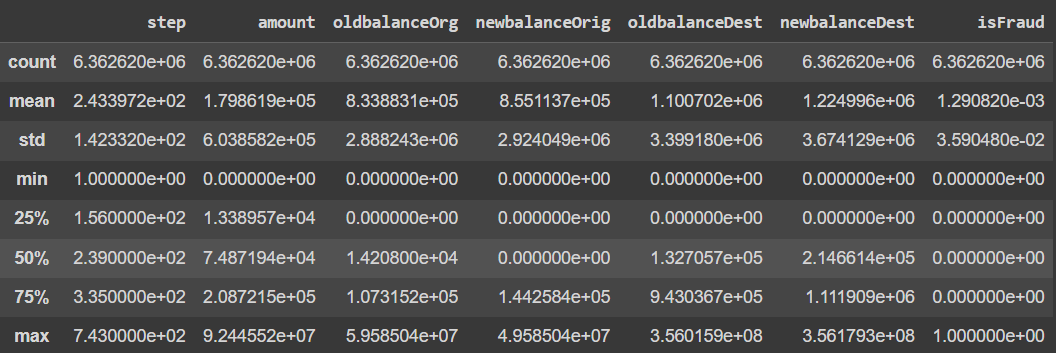
Let's see the mean, count , minimum and maximum values of the data.
Output :
In this section, we will try to understand and compare all columns.
Let's count the columns with different datatypes like Category, Integer, Float.
Output :
Categorical variables: 3
Integer variables: 2
Float variables: 5
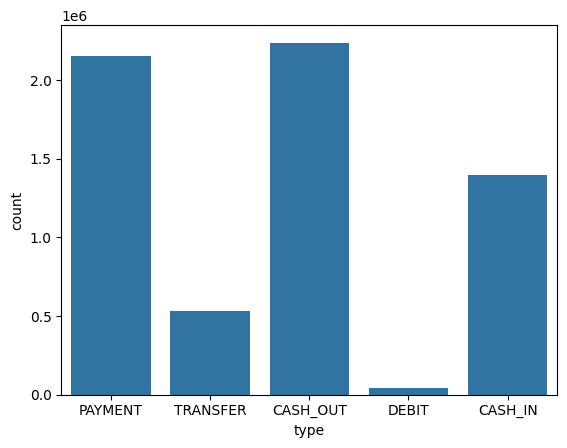
Let's see the count plot of the Payment type column using Seaborn library.
Output :
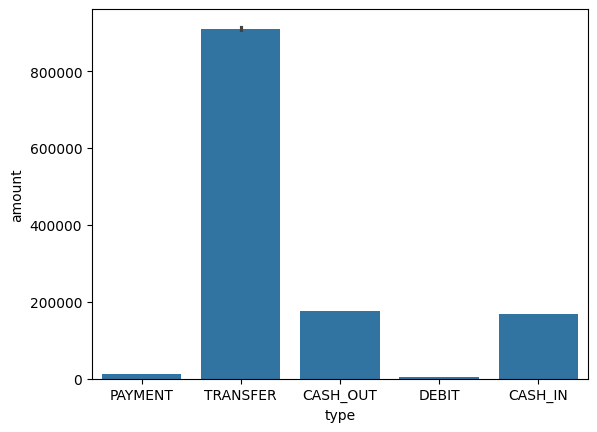
We can also use the bar plot for analyzing Type and amount column simultaneously.
Output :
Both the graph clearly shows that mostly the type cash_out and transfer are maximum in count and as well as in amount.
Let's check the distribution of data among both the prediction values.
Output :
isFraud count
0 6354407
1 8213
The dataset is already in same count. So there is no need of sampling.
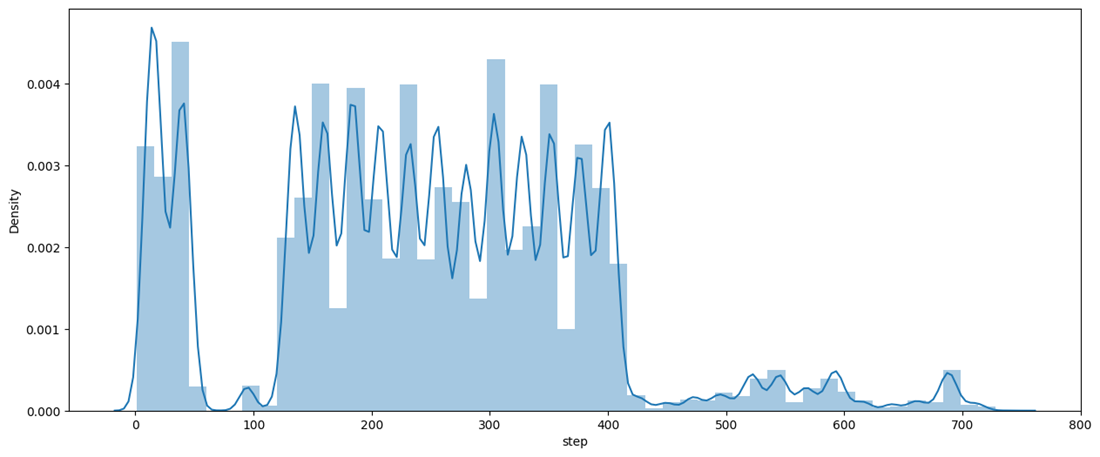
Now let's see the distribution of the step column using distplot.
Output :
The graph shows the maximum distribution among 200 to 400 of step.
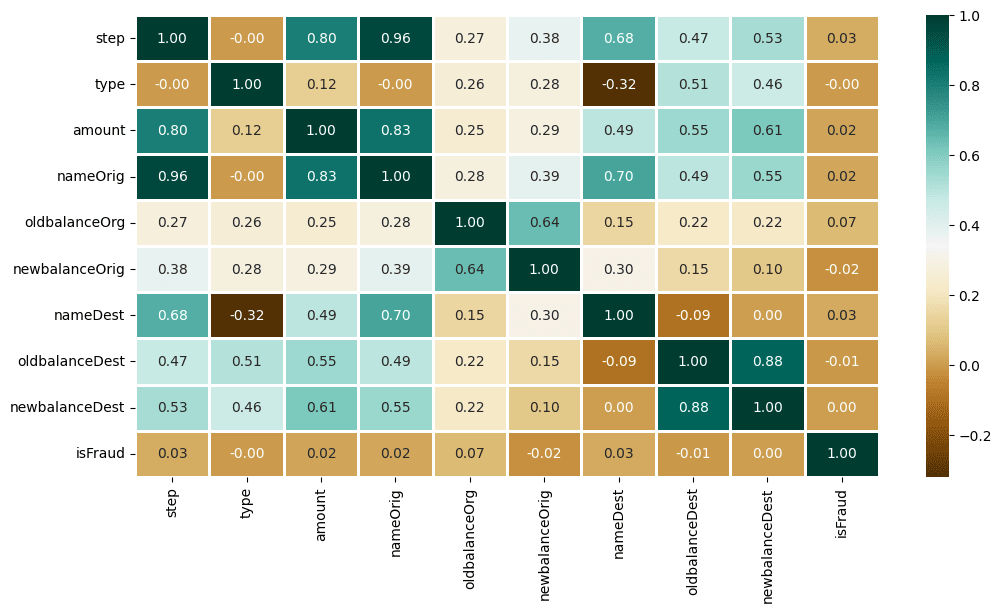
Now, Let's find the correlation among different features using Heatmap.
Output :
This step includes the following :
Output:
Once we done with the encoding, now we can drop the irrelevant columns. For that, follow the code given below.
Let's check the shape of extracted data.
Output:
((6362620, 10), (6362620,))Now let's split the data into 2 parts : Training and Testing.
As the prediction is a classification problem so the models we will be using are :
Let's import the modules of the relevant models.
Once done with the importing, Let's train the model.
Output:
LogisticRegression() :
Training Accuracy : 0.8873984626066378
Validation Accuracy : 0.8849956507155117
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=None, n_jobs=None,
num_parallel_tree=None, random_state=None, ...) :
Training Accuracy : 0.9999774189140321
Validation Accuracy : 0.999212631773824
RandomForestClassifier(criterion='entropy', n_estimators=7, random_state=7) :
Training Accuracy : 0.9999992716004644
Validation Accuracy : 0.9650098729693373
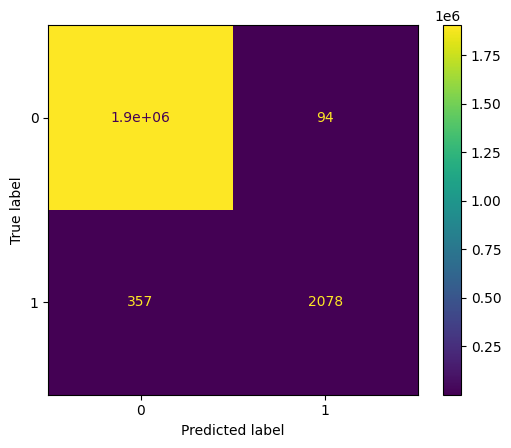
The best-performed model is XGBClassifier. Let's plot the Confusion Matrix for the same.
Output:
You can download the dataset and source code from here:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}