 |
VOOZH | about |
|
VOOZH | about |
Spectral clustering is a technique used in machine learning and data analysis for grouping data points based on their similarity. The method involves transforming the data into a representation where the clusters become apparent and then using a clustering algorithm on this transformed data. In R Programming Language spectral clustering, the transformation is done using the eigenvalues and eigenvectors of a similarity matrix.
There are some components that we used in Spectral Clustering in the R Programming Language.
Spectral clustering works by transforming the data into a lower-dimensional space where clustering is performed more effectively. The key steps involved in spectral clustering are as follows:
Start with a dataset of data points. Compute an affinity or similarity matrix that quantifies the relationships between these data points. This matrix reflects how similar or related each pair of data points is. Common affinity measures include Gaussian similarity, k-nearest neighbors, or a user-defined similarity function.
Interpret the affinity matrix as the adjacency matrix of a weighted undirected graph. In this graph, each data point corresponds to a vertex, and the weight of the edge between vertices reflects the similarity between the corresponding data points.
Construct the graph Laplacian matrix, which captures the connectivity of the data points in the graph. There are two main types of Laplacian matrices used in spectral clustering.
Compute the eigenvalues (λ_1, λ_2, ..., λ_n) and the corresponding eigenvectors (v_1, v_2, ..., v_n) of the Laplacian matrix. You typically compute a few eigenvectors, corresponding to the smallest non-zero eigenvalues.
Use the selected eigenvectors to embed the data into a lower-dimensional space. The eigenvectors represent new features that capture the underlying structure of the data. The matrix containing these eigenvectors is referred to as the spectral embedding.
Apply a clustering algorithm to the rows of the spectral embedding. Common clustering algorithms like k-means, normalized cuts, or spectral clustering can be used to group the data points into clusters in this lower-dimensional space.
The key idea behind spectral clustering is that by using spectral embeddings, We can potentially find clusters that are not easily separable in the original feature space. The choice of the number of clusters and the number of eigenvectors to retain in the embedding space often depends on domain knowledge, data characteristics, and application-specific requirements.
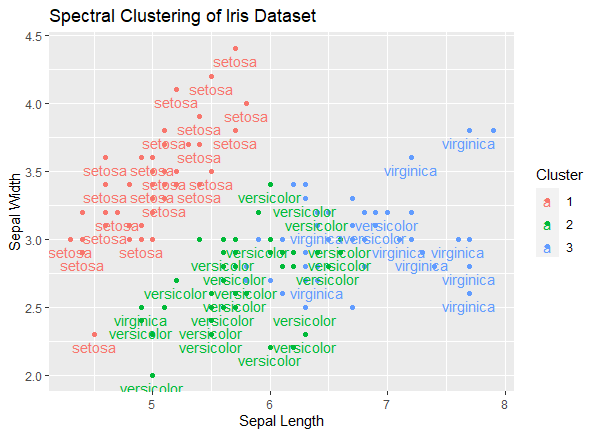
Now we will take the iris dataset for clustering.
Output:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species Cluster
1 5.1 3.5 1.4 0.2 setosa 1
2 4.9 3.0 1.4 0.2 setosa 1
3 4.7 3.2 1.3 0.2 setosa 1
4 4.6 3.1 1.5 0.2 setosa 1
5 5.0 3.6 1.4 0.2 setosa 1
6 5.4 3.9 1.7 0.4 setosa 1
A similarity matrix is created. This matrix quantifies the similarity between data points using the Euclidean distance as a similarity measure.
Output:
ggplot(iris, aes(Sepal.Length, Sepal.Width, color = Cluster, label = Species)): This sets up the initial plot using the iris dataset. It specifies that the x-axis should represent Sepal.Length, the y-axis should represent Sepal.Width, and the color of the points should be determined by the 'Cluster' column. Additionally, the 'label' aesthetic is set to 'Species' to label the data points with the species names.
Output:
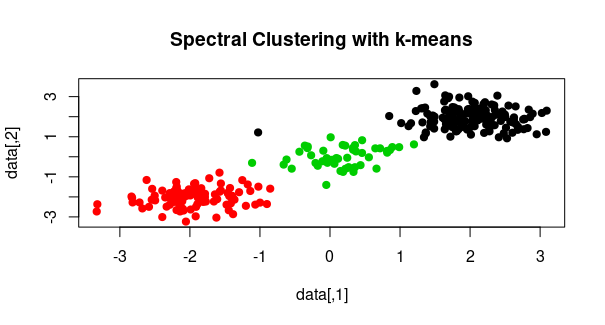
First generates a random dataset with three clusters. It sets the random seed for reproducibility and creates data points using the rnorm function, which generates random numbers from a normal distribution. We stack these data points using rbind to create the dataset.
eigen function to perform the eigen-decomposition of the similarity_matrix. The result, stored in eigen_result, contains eigenvalues and eigenvectors.k_eigenvectors. The k parameter specifies the number of clusters, and the resulting cluster assignments are stored in cluster_assignments.col parameter is set to cluster_assignments to color the points according to their assigned clusters.Output:
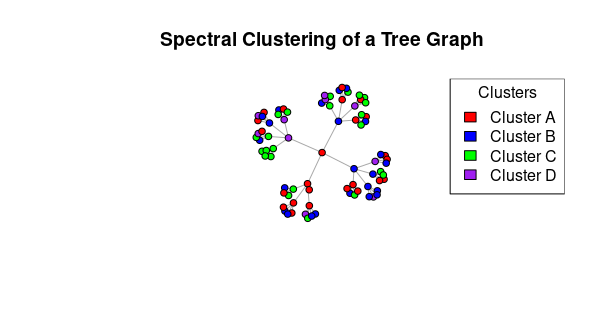
First loads the igraph library, which is a package in R used for creating and analyzing network graphs and structures.
We define cluster_colors and cluster_labels. cluster_colors is a vector of color names, and cluster_labels is a vector of labels corresponding to each cluster. These will be used in the plot and legend.
Finally, this code adds a legend to the plot. It specifies the position ("topright") of the legend, the labels (cluster_labels) for each cluster, the fill colors (cluster_colors), and a title for the legend ("Clusters"). This legend provides a visual reference to the cluster assignments and their associated colors on the graph.
{kind=link}
{kind=link}
{kind=link}
{kind=link}