 |
VOOZH | about |
|
VOOZH | about |
XGBoost (Extreme Gradient Boosting) is an optimized and scalable implementation of the gradient boosting framework designed for supervised learning tasks such as regression and classification. In regression, XGBoost aims to predict continuous numeric values by minimizing loss functions (e.g., RMSE or MSE) while incorporating regularisation to prevent overfitting.
XGBoost is particularly effective for regression problems due to:
XGBoost constructs its models by minimizing an objective function that balances two aspects:
Formally, the objective function is:
Where:
XGBoost supports multiple loss functions depending on the task:
1. Regression (continuous target):
This is also referred to as squared error loss ("reg:squarederror" in XGBoost). It penalizes larger errors more heavily, which is suitable for regression tasks where extreme deviations matter.
2. Binary Classification (0/1 target):
This is logistic loss ("reg:logistic") and is used when predictions are probabilities between 0 and 1.
1. During tree building, XGBoost calculates gain for each possible split:
2. A split is accepted only if Gain > 0, ensuring that the split improves the model after considering regularization.
3. Leaf weights are calculated as:
This shows how L2 regularization (λ) shrinks leaf weights and L1 (α) further encourages zero weights.
Lets install the XGBoost package,
Here we will load seaborn and pandas library. We will use the mpg dataset from Seaborn to show the working.
We will convert categorical features into numerical values using one-hot encoding.
Split the data into training and testing sets where 70% data will be used for training and rest for testing.
We will train the XGBoost Regressor.
Output:
RMSE: 2.967
R²: 0.834
We get optimized model performance with GridSearchCV.
Output:
Fitting 3 folds for each of 36 candidates, totalling 108 fits
Best parameters: {'colsample_bytree': 0.8, 'learning_rate': 0.1, 'max_depth': 3, 'subsample': 0.8}
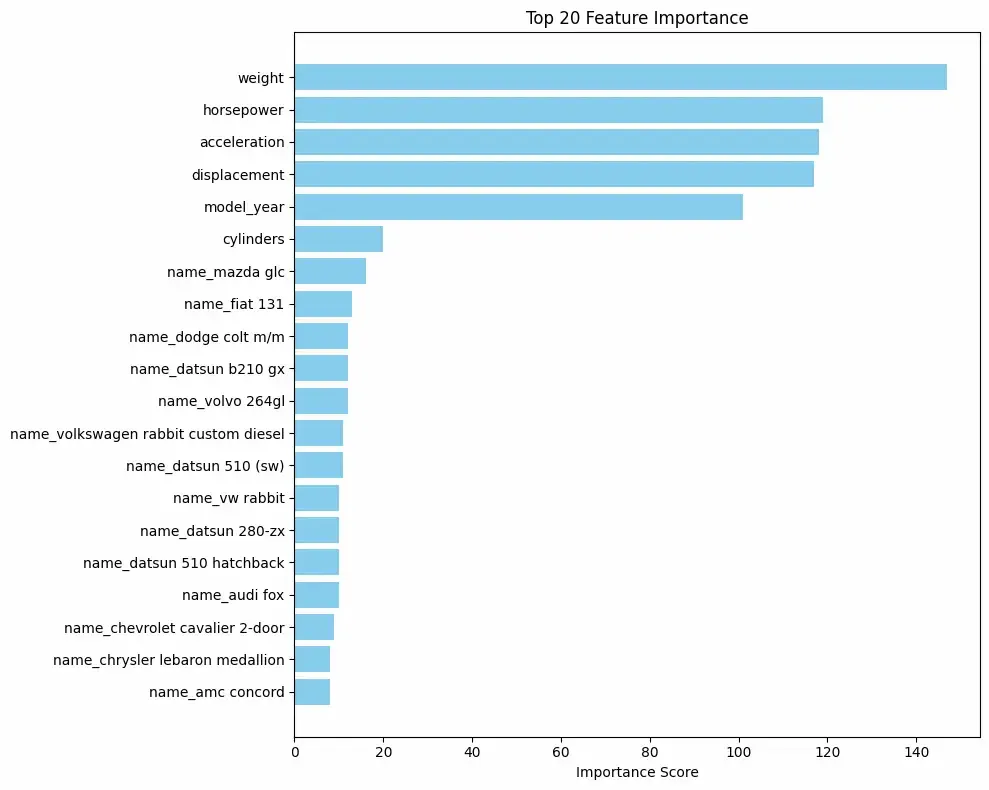
We will plot the top important features.
Output:
{kind=link}
{kind=link}