 |
VOOZH | about |
|
VOOZH | about |
The PostgreSQL CUME_DIST() function is a powerful analytical tool used to determine the relative position of a value within a set of given values. This function helps compute the cumulative distribution of values in a result set, which can be particularly useful in statistical analysis and reporting.
Let us better understand the CUME_DIST Function in PostgreSQL from this article.
CUME_DIST() OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sorting_expression [ASC | DESC], ...
)
The CUME_DIST()function returns a double-precision value between 0 and 1:
0 < CUME_DIST() <= 1Let us take a look at some of the examples of CUME_DIST Function in PostgreSQL to better understand the concept.
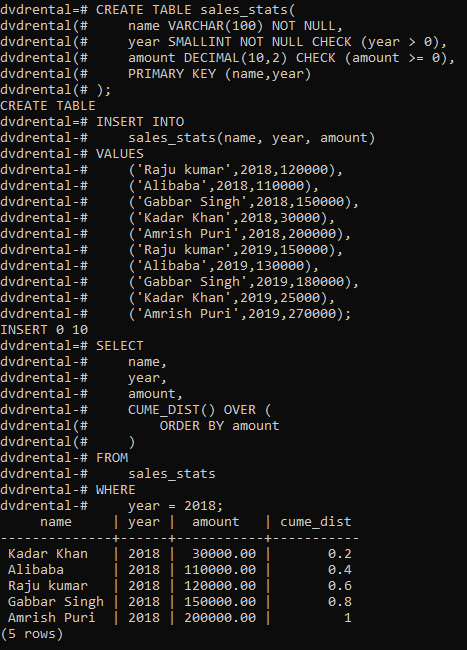
First, create a table named 'sales_stats' that stores the sales revenue by employees:
The following query returns the sales amount percentile for each sales employee in 2018.
Query:
SELECT
name,
year,
amount,
CUME_DIST() OVER (
ORDER BY amount
)
FROM
sales_stats
WHERE
year = 2018;
Output:
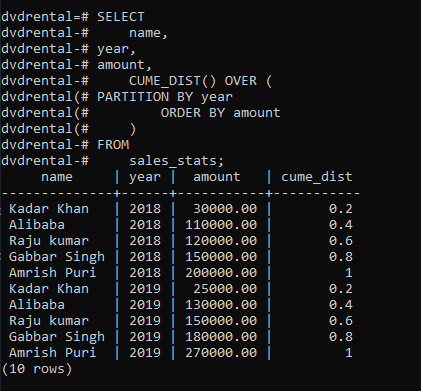
👁 PostgreSQL CUME_DIST Function ExampleThe following query uses the CUME_DIST()function to calculate the sales percentile for each sales employee in 2018 and 2019.
Query:
SELECT
name,
year,
amount,
CUME_DIST() OVER (
PARTITION BY year
ORDER BY amount
)
FROM
sales_stats;
Output:
👁 PostgreSQL CUME_DIST Function Example
- The
CUME_DIST()function calculates the cumulative distribution of a value in a dataset.- When there are ties (duplicate values) in the ordering column,
CUME_DIST()assigns the same cumulative distribution value to each tied row.- The result of
CUME_DIST()is in double-precision. Be mindful of this when performing further calculations or comparisons with the result.- CUME_DIST() and PERCENT_RANK() both return values between 0 and 1, but they differ in calculation. CUME_DIST() shows the proportion of rows with values less than or equal to the current row, while PERCENT_RANK() indicates the relative rank of the current row within the partition.
{kind=link}
{kind=link}
{kind=link}