 |
VOOZH | about |
|
VOOZH | about |
ETL testing ensures that data is correctly extracted from source systems, transformed as per business rules, and loaded accurately into target systems. It plays a key role in maintaining data quality, consistency, and reliability in data warehouses and BI systems.
To help you get started, we've compiled a list of common ETL interview questions specifically for beginners. These questions cover fundamental concepts such as the ETL process, data warehousing, common tools, and basic troubleshooting techniques.
ETL (Extract, Transform, Load) is a data integration process that helps clean, combine, and organize data from multiple sources into a single, consistent storage system like a data warehouse or data lake.
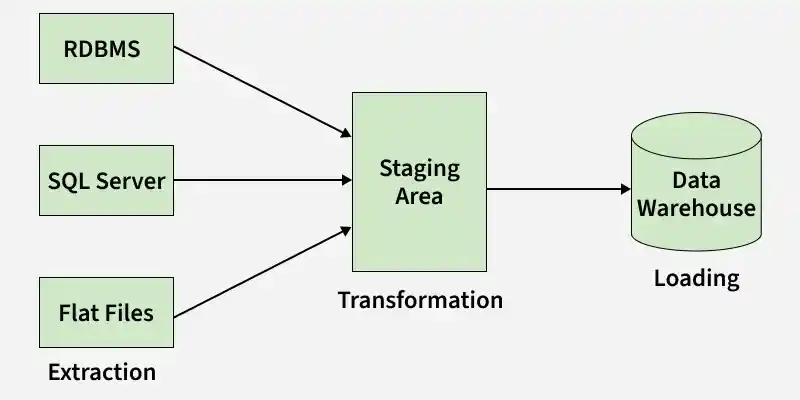
An ETL data pipeline forms the foundation for data analytics and machine learning. It follows three main steps:
ETL testing includes different types that ensure data accuracy, consistency, and performance across the data pipeline. Each type focuses on validating a specific stage of the ETL process.
ETL testing is about making sure that data is correctly moved from one place to another, changed as needed, and saved correctly in its final location. Here’s an overview of the ETL testing process:
ETL tools are used to extract, transform, and load data from multiple sources into a data warehouse efficiently and accurately.
Here's a list of the best ETL testing tools.
1. Enterprise Tools:
2. Open-Source Tools:
3. Cloud-Based Tools:
Following are the importance of ETL testing:
An ETL pipeline is a set of operations that transport data from one or more sources to a database, such as a data warehouse. ETL stands for "extract, transform, load," which refers to the three interdependent data integration operations that move data from one database to another.
Following are the role and responsibilities of an ETL tester
Three-layer architecture of an ETL cycle are:
Business intelligence refers to a collection of mathematical models and analysis methods that utilize data to produce valuable information and insight for making important decisions. BI test validates staging data, the ETL process, and BI reports to ensure their reliability. Essentially, BI involves gathering raw business data and converting it into actionable insights. BI Testing verifies the accuracy and credibility of these insights derived from the BI process.
The primary difference between ETL Testing and Database Testing are:
| ETL Testing | Database Testing |
|---|---|
| Verifies data extraction, transformation, and loading process | Verifies database functionality and data integrity |
| Focuses on data movement between source and target systems | Focuses on database tables, schema, triggers, and stored procedures |
| Checks data transformation rules and mappings | Checks CRUD operations and database constraints |
| Commonly used in data warehouses and BI systems | Commonly used in application databases |
| Ensures data is correctly loaded into target systems | Ensures database operations work correctly |
| Tests data quality, completeness, and accuracy | Tests database performance and consistency |
| Tools: Informatica, Talend | Tools: MySQL, Oracle Database |
In ETL (Extract, Transform, Load) testing, various types of data sources can be tested to ensure the accuracy, completeness, and integrity of the data as it moves through the ETL process.
Data cleansing is the process of discovering and repairing mistakes, inconsistencies, and abnormalities in source data before loading it into the target data warehouse. This ensures data quality and integrity, as well as the reliability and accuracy of analytical and reporting operations.
Data purging is the process of permanently removing old, obsolete, or unwanted data from source, staging, or target systems as per business rules to optimize performance and storage.
In ETL testing, testers verify that purging rules are correctly implemented—ensuring that only eligible data is removed, it is deleted from all relevant layers (source/staging/warehouse), and no required historical or active data is accidentally lost.
A data mart is a smaller, focused version of a data warehouse designed for a specific department like sales, finance, or HR. It provides relevant data to a particular group of users, helping them analyze information quickly and efficiently. Since it stores only required data, it improves query performance and speeds up data retrieval for faster decision-making.
A data source view (DSV) is a crucial component of a data warehouse that serves as a bridge between the data sources and the data warehouse. It is a logical representation of the data sources added to a data warehouse. It defines the structure, relationships, and metadata of these data sources, offering a unified and consistent view of the data for developers and users.
Key Aspects:
ETL testing is a subset of total DWH testing. A data warehouse is primarily constructed through data extractions, transformations, and loads. ETL methods extract data from sources, convert it in accordance with BI reporting needs, and then load it into the destination data warehouse.
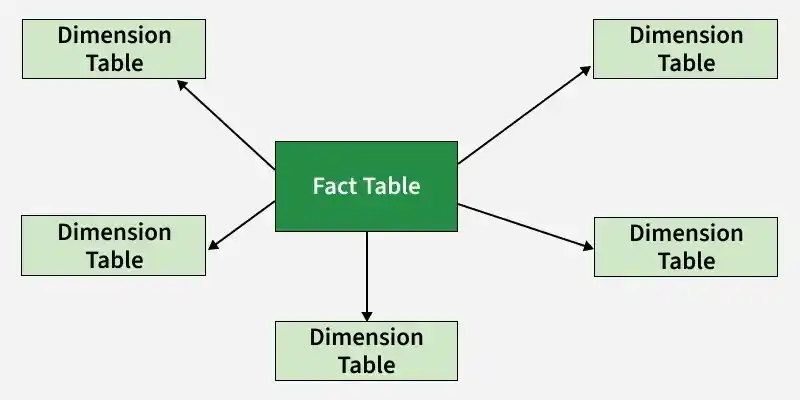
A fact table contains measures used in any business function, such as metrics or facts. It is surrounded by dimensions and connects to a dimension table. It is surrounded by dimensions and includes sales data such as Product and Price.
Facts in ETL are classified into the following types:
A dimension table is a table in a data warehouse that stores descriptive information (context) about business entities such as customer, product, time, or location. It is used to provide meaning to the numerical data stored in fact tables. For example, a time dimension table may contain year, month, day, and quarter.
A fact table stores quantitative data (measures or metrics) such as sales amount, quantity sold, profit, etc. It represents business transactions or events.
Given below is the Difference between Fact Table and Dimension Table:
| Aspect | Dimension Table | Fact Table |
|---|---|---|
| Definition | Stores descriptive attributes about business entities | Stores numerical metrics or measurements |
| Data Type | Textual / categorical data | Numeric data |
| Purpose | Provides context to facts | Stores business performance data |
| Schema Position | Connected to fact table in star schema | Central table in star schema |
| Keys | Has primary key | Contains foreign keys from dimension tables |
| Hierarchy | May contain hierarchies (e.g., time, geography) | Does not contain hierarchies |
| Example | Product, Customer, Time tables | Sales, Order, Revenue tables |
You can ensure the accuracy and completeness of data in ETL testing through the following methods:
Following are the differences between Data Validation Testing and Data Transformation Testing:
| Aspect | Data Validation Testing | Data Transformation Testing |
|---|---|---|
| Purpose | Ensures that data extracted from the source system is accurate, complete, and meets quality standards before processing. | Ensures that data is correctly transformed from source format to target format as per business rules. |
| Focus | Focuses on data quality such as completeness, accuracy, and correctness of raw data. | Focuses on verifying transformation rules like mapping, calculations, and data type conversions. |
| Activities | Includes record count checks, format validation, and checking data correctness. | Includes verifying transformations, derived calculations, and data mapping logic. |
| Timing | Performed before transformation. | Performed after validation during or after transformation. |
| Objective | Ensures only clean and valid data is processed further. | Ensures transformed data matches business and ETL requirements. |
The primary differences between power mart and power center are:
Aspect | Power Mart | Power Center |
|---|---|---|
Data Processing | Suitable for processing small amounts of data with low processing requirements. | Ideal for handling large volumes of data quickly and efficiently. |
ERP Support | Does not support ERP sources. | Supports ERP sources such as SAP, PeopleSoft, etc. |
Repository Support | Only supports local repositories. | Supports both local and global repositories. |
Repository Conversion | No capability to convert local repositories to global ones. | Can convert local repositories into global repositories. |
Session Partitioning | Does not support session partitioning. | Supports session partitioning to enhance ETL performance. |
Different challenges in ETL Testing are:
Following are the best practices of ETL Testing:
Following are thedifferences between data warehouse and data mining.
| Basis of Comparison | Data Warehousing | Data Mining |
|---|---|---|
| Definition | A data warehouse is a database system that is designed for analytical analysis instead of transactional work. | Data mining is the process of analyzing data patterns. |
| Process | Data is stored periodically. | Data is analyzed regularly. |
| Purpose | Data warehousing is the process of extracting and storing data to allow easier reporting. | Data mining is the use of pattern recognition logic to identify patterns. |
| Managing Authorities | Data warehousing is solely carried out by engineers. | Data mining is carried out by business users with the help of engineers. |
| Data Handling | Data warehousing is the process of pooling all relevant data together. | Data mining is considered as a process of extracting data from large data sets. |
| Functionality | Subject-oriented, integrated, time-varying and non-volatile constitute data warehouses. | AI, statistics, databases, and machine learning systems are all used in data mining technologies. |
| Task | Data warehousing is the process of extracting and storing data in order to make reporting more efficient. | Pattern recognition logic is used in data mining to find patterns. |
| Uses | It extracts data and stores it in an orderly format, making reporting easier and faster. | This procedure employs pattern recognition tools to aid in the identification of access patterns. |
| Examples | When a data warehouse is connected with operational business systems like CRM (Customer Relationship Management) systems, it adds value. | Data mining aids in the creation of suggestive patterns of key parameters. Customer purchasing behavior, items, and sales are examples. As a result, businesses will be able to make the required adjustments to their operations and production. |
In order to use ETL in Data Warehousing, follow these steps:
In summary, ETL processes extract data from multiple sources, transform it into a suitable format, and load it into a data warehouse for combined historical and current data analysis.
Following are the types of Data warehouse System:
Once you have gone through beginner level, then explorer this section to get an advanced level ETL interview questions. Here you will get compiled list of interview questions for ETL testing.
A Slowly Changing Dimension (SCD) is a method used in data warehousing to manage changes to dimension data over time.
There are three main types of SCD
| Aspect | ETL Tools | OLAP Tools |
|---|---|---|
Function | ETL (Extract, Transform, Load) tools prepare data for analysis by moving and formatting it into data warehouses or data marts. | OLAP (Online Analytical Processing) tools analyze and present data for insights through interactive queries and reports |
Primary Use | Used to integrate and consolidate data from various sources for analysis. | Used to explore and analyze data stored in databases or data warehouses. |
Tasks | Perform tasks like data extraction, transformation (e.g., cleaning, formatting), and loading into target systems. | Perform tasks like creating multidimensional views of data, aggregating information for reports, and enabling interactive data analysis. |
Focus | Focuses on data movement, transformation, and preparation for analysis. | Focuses on data analysis, querying, and reporting to derive insights. |
Examples | Examples include Informatica PowerCenter, Talend, SSIS (SQL Server Integration Services). | Examples include Microsoft Analysis Services (SSAS), IBM Cognos, Oracle OLAP. |
A data warehouse schema defines how data entities, such as fact tables and dimension tables, are organized and related within the data warehouse system. It specifies the logical structure and arrangement of these entities to facilitate efficient data storage, retrieval, and analysis. The schema helps establish how data is integrated and stored for optimized querying and reporting in the data warehouse environment.
Following are the different types of Schemas in Data Warehouse:
A star schema is a type of data warehouse schema used to organize data in a simple and efficient way for analysis and reporting. It is widely used in data warehouses, data marts, and BI systems.
In a star schema, there is a single central fact table that stores quantitative data such as sales amount, quantity, or revenue. This fact table is connected to multiple dimension tables through foreign key relationships.
The dimension tables store descriptive information such as product details, customer information, or time data, which provide context to the facts.
A snowflake schema is a type of data warehouse schema where dimension tables are normalized into multiple related tables, forming a hierarchical structure. It is used to organize data efficiently and reduce redundancy.
In a snowflake schema, the fact table is placed at the center and connected to dimension tables, which are further normalized into sub-dimension tables. This creates a snowflake-like structure.
For example:
It improves data consistency and reduces redundancy but requires more complex joins during queries.
Given below are the differences between ETL TestingandManual Testing:
Aspect | ETL Testing | Manual Testing |
|---|---|---|
Definition | ETL (Extract, Transform, Load) testing is an automated process used to validate, verify, and ensure that data is accurately and correctly transferred from source systems to a data warehouse or data repository | Manual testing is a process where testers manually execute test cases without using any automation tools, focusing on ensuring the program's functionality and finding defects. |
Process Speed | Automated, very fast, and systematic with excellent results. | Time-consuming and highly prone to errors. |
Focus | Central to databases and their counts. | Focuses on the program's functionality. |
Metadata | Includes metadata which is easy to modify. | Lacks metadata, making changes more labor-intensive. |
Error Handling and Maintenance | Handles errors, log summaries, and load progress efficiently, easing the workload. | Requires maximum effort for maintenance. |
Handling Historical Data | Efficient at managing historical data. | Processing time increases as data grows. |
Following are the types of ETL bugs:
An OLAP (Online Analytical Processing) cube is a data structure that enables quick analysis of data from multiple perspectives or dimensions. It is designed to provide rapid answers to complex queries by organizing data in a multidimensional format.
An Operational Data Store (ODS) is a database that stores real-time or near real-time data collected from multiple source systems. It is used to support operational reporting and quick decision-making.
An ODS integrates and cleans data from different sources to ensure consistency and accuracy. Unlike a data warehouse, it contains current, detailed operational data rather than historical data.
It is often used for short-term storage and fast reporting, and may later feed data into a data warehouse for long-term analytical processing.
Bus Schema is a dimensional modeling approach used in data warehouses where multiple fact tables share common (conformed) dimensions. These shared dimensions act like a “bus” that allows different business processes to be analyzed consistently across the enterprise.
It is called a “bus architecture” because the conformed dimensions act like a standard communication backbone that connects different fact tables, enabling integration across business areas like sales, finance, and inventory.
The efficiency and performance of a Datareader Destination Adapter in ETL are significant benefits. The Datareader Adapter enables for rapid and direct data loading into a target database, eliminating the need for extra transformation or processing.
In ETL testing, the grain of a fact table is the level of detail that each row of a fact table represents. The grain of a fact table is based on requirements findings that were analyzed and documented in the first step of the process, which is to identify business process requirements.
A staging area in ETL testing is a buffer zone where raw data extracted from source systems is temporarily stored. It acts as a holding area where data is cleansed, transformed, and standardized before being loaded into the final destination (e.g., data warehouse).
In ETL (Extract, Transform, Load) operations, a lookup is a process used to retrieve a specific value or an entire dataset based on input parameters. It involves querying a database or another data source to find and return the required information, often to calculate a field's value or to enhance the data with additional details.
Following are the differences between Star Schema and Snowflake Schema:
| Aspect | Star Schema | Snowflake Schema |
|---|---|---|
| Definition | In star schema, The fact tables and the dimension tables are contained. | While in snowflake schema, The fact tables, dimension tables as well as sub dimension tables are contained. |
| Model | Star schema is a top-down model. | While it is a bottom-up model. |
| Space | Star schema uses more space. | While it uses less space. |
| Time | It takes less time for the execution of queries. | While it takes more time than star schema for the execution of queries. |
| Normalization | In star schema, Normalization is not used. | While in this, Both normalization and denormalization are used. |
| Design | It’s design is very simple. | While it’s design is complex. |
| Query Complexity | The query complexity of star schema is low. | While the query complexity of snowflake schema is higher than star schema. |
| Ease to Understand | It’s understanding is very simple. | While it’s understanding is difficult. |
| Foreign Keys | It has less number of foreign keys. | While it has more number of foreign keys. |
| Data Redundancy | It has high data redundancy. | While it has low data redundancy. |
I would first check the source data for null values, then verify mapping documents and transformation logic. Next, I would review ETL logs for errors or rejected records, fix the issue, rerun the ETL job, and validate the target data for accuracy and completeness.
I would analyze ETL logs to identify bottlenecks, optimize database queries and indexes, and improve batch or parallel processing. Finally, I would perform load testing to verify performance improvements.
I would validate incremental extraction using timestamps or keys, verify transformation rules, and perform end-to-end testing to ensure no duplicate or missing records exist in the target system.
I would compare source and target record counts, validate transformation rules, and perform data reconciliation using aggregates and sample data to ensure accurate migration without data loss or duplication.
I would verify foreign key and primary key relationships between fact and dimension tables, validate ETL mappings, and reconcile business metrics like SUM and COUNT with source system data to ensure accuracy.
{kind=link}
-testing-copy.webp){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}
{kind=link}