Distributed Data Parallel (DDP) is a technique that enables the training of deep learning models across multiple GPUs and even multiple machines. By splitting data and computations, DDP accelerates training, improves scalability and makes efficient use of hardware resources important for large-scale AI projects.As modern neural networks and datasets grow in size and complexity, single GPU or even single machine training becomes impractical DDP addresses this by splitting the workload, reducing training time and unlocking scalability for enterprise and research applications.
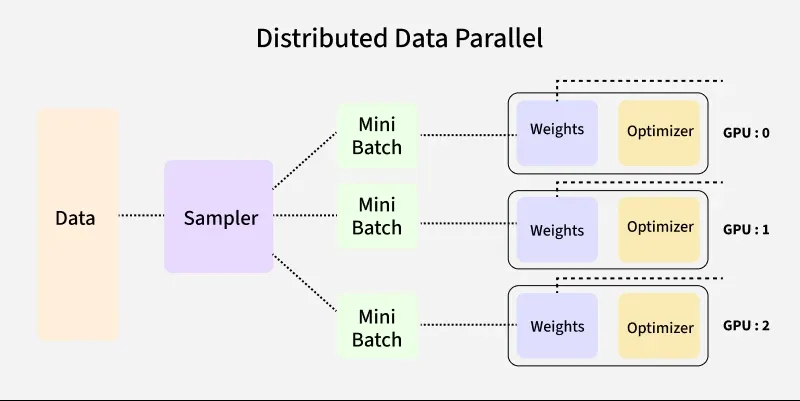
The training dataset is divided into mini-batches.
Each mini-batch is assigned to a separate GPU (or process), with each GPU holding a replica of the model.
2. Forward and Backward Passes
Each GPU processes its mini-batch independently, performing forward and backward passes to compute gradients for its data subset.
3. Gradient Synchronization with All-Reduce
After the backward pass, each GPU has its own set of gradients. DDP uses the all-reduce operation to synchronize and average these gradients across all GPUs.
All-reduce is a collective communication operation that aggregates data (e.g., sums gradients) from all processes and distributes the result back to each process.
This ensures that every model replica receives the same averaged gradients, keeping models in sync.
4. Parameter Update
Each GPU updates its model parameters using the synchronized gradients.
The process repeats for each training iteration, ensuring consistent model updates across all devices.
Formula
where:
is the gradient computed on the ithith GPU (or process) for its mini-batch.
is the total number of GPUs (or processes).
The all-reduce operation sums all gradients and distributes the result back to all GPUs. Each GPU then averages the sum by dividing by .
This ensures that every GPU has the same averaged gradient before updating the model parameters synchronously.
Key Components
Model Replication: Each GPU/process has a full copy of the model.
Data Sharding: Input data is split so each GPU works on a unique subset.
Gradient Averaging: All-reduce ensures all GPUs have identical gradients before updating parameters.
Synchronization: DDP uses hooks and reducers to trigger all-reduce at the right time during backpropagation.
Comparison to Other Parallelization Techniques
DataParallel (single-process, multi-thread) is limited to a single machine and is generally slower due to Python’s Global Interpreter Lock (GIL) and extra overhead.
Model Parallelism splits the model itself across devices, useful for extremely large models but more complex to implement.
Advantages of Distributed Data Parallel
Scalability: Easily scales training across many GPUs and machines, achieving near-linear speedup as more resources are added.
Faster Training: Reduces time to convergence for large models and datasets by parallelizing computation.

{kind=link}
{kind=link}