Multi-Task Learning (MTL) is a machine learning approach where a single model learns multiple related tasks simultaneously using shared representations, improving generalization and reducing overfitting.
Learn multiple related tasks using a single model
Improve generalization and reduce overfitting
Make efficient use of limited training data
Reduce computational cost compared to training separate models
Widely used in computer vision, NLP and healthcare systems
Suppose a face analysis system needs to perform multiple tasks simultaneously:
Face detection
Age prediction
Gender classification
Step 1: Input Data
The input image is provided to the neural network. The same input is shared across all tasks.
Step 2: Shared Feature Extraction
The initial layers of the network act as a shared feature extractor. These layers learn common patterns such as
Edges
Facial shapes
Textures
Facial structures
Since these features are useful for all tasks, they are learned only once and shared across the model.
Step 3: Task-Specific Layers
After extracting common features, the network splits into multiple task-specific branches called task heads.
One branch performs face detection
Another predicts age
Another classifies gender
Each branch learns features specific to its own task.
Step 4: Simultaneous Training
All tasks are trained together using a combined loss function. During training:
Shared layers learn generalized representations
Task-specific layers optimize for their individual objectives
Knowledge from one task helps improve learning in related tasks
Step 5: Final Predictions
The trained model produces multiple outputs from a single input image:
Detected face location
Predicted age
Predicted gender
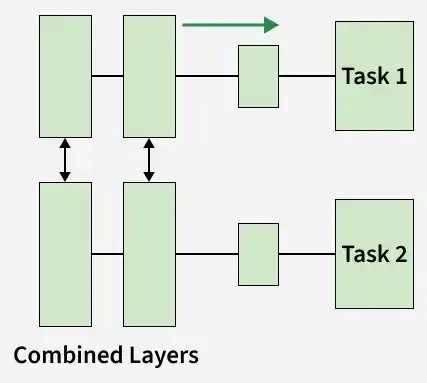
Techniques of MTL
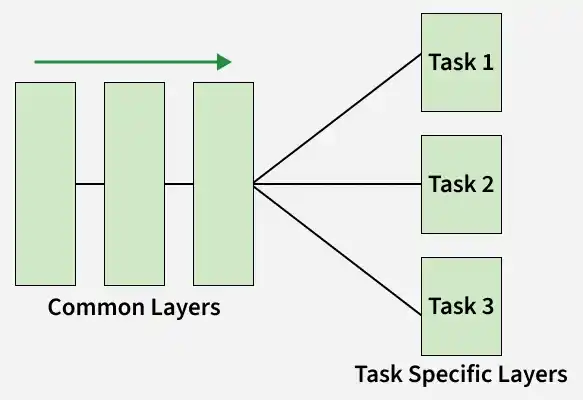
HardParameterSharing
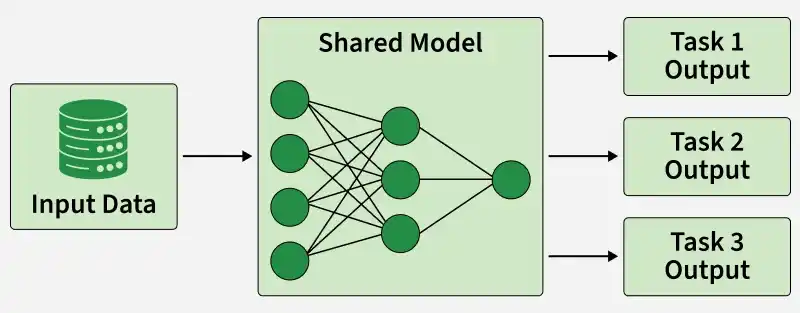
Hard parameter sharing is the most commonly used technique in MTL, where multiple tasks share the same hidden layers of a neural network and only the output layers are different.
Input data passes through shared layers
These layers learn common features (patterns useful for all tasks)
Output is then split into task-specific heads
Each head produces prediction for a different task

{kind=link}
{kind=link}
{kind=link}
{kind=link}