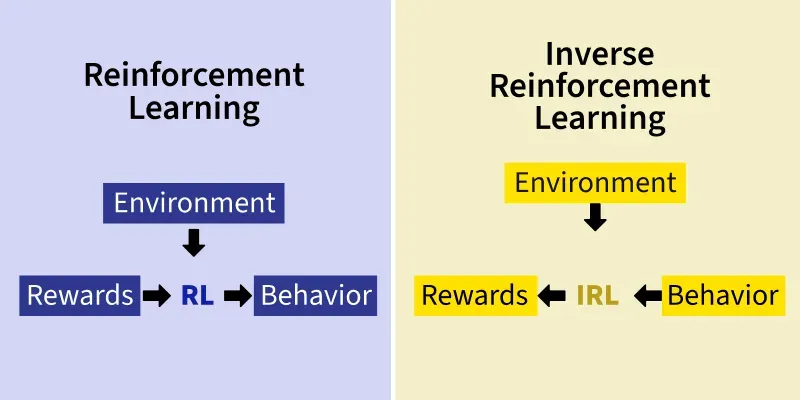
In traditional reinforcement learning (RL), an agent learns a policy (behavior strategy) by maximizing a known reward function. Inverse Reinforcement Learning reverses this i.e. instead of learning policy from reward function inverse reinforcement learning learns reward function from policy and hence the :
Input: Expert demonstrations (trajectories of states and actions).
Output: Learned reward function that explains the expert's behavior.
Goal: Discover the hidden objectives the expert was optimizing.
Expert Trajectory: Human driver slows down near schools, stops at yellow lights.
IRL Infers Reward: (Learns that safety > speed near schools)
Result: Self-driving car generalizes to unseen scenarios (e.g., construction zones) because it understands objectives, not just actions.
Why IRL Excels with Limited Data
Imitation Learning Failure: If an expert never encounters a rare scenario (e.g., deer on road), imitation fails.
IRL Solution: Infers that avoiding collisions is a core reward -> applies to deer scenario even without explicit data.
Key Challenges of Inverse Reinforcement Learning (IRL)
Reward Ambiguity: Multiple reward functions can explain the same expert behavior, making it hard to identify the true intent.
Data Limitations: Limited, noisy, or suboptimal expert demonstrations can mislead the learned reward and policy.
Computational Complexity: IRL often requires repeatedly solving RL problems, making it computationally expensive, especially for large or continuous state spaces.
Generalization Issues: Learned rewards may overfit to demonstration data and fail in unseen scenarios; generalizing from few demonstrations is challenging.
Sensitivity to Prior Knowledge: IRL results can depend heavily on the choice of features and prior assumptions.
Task Alignment: Focusing only on matching demonstration data (data alignment) can lead to rewards that do not capture the true task objectives, resulting in misaligned or exploitable policies.

{kind=link}
{kind=link}