 |
VOOZH | about |
|
VOOZH | about |
In traditional reinforcement learning, an agent learns by receiving rewards from the environment for example, a robot gets a point for reaching a goal, or a game-playing AI gets a score for winning. These are called extrinsic rewards because they come from outside the agent and are directly tied to the task.
However, many real-world environments are sparse in rewards. Imagine a robot exploring a new building: it might only get a reward after finding a particular room, but there’s no feedback for all the steps it takes before that. In such cases, the agent might struggle to learn, because it doesn’t know which actions are useful until it stumbles upon a reward by chance.
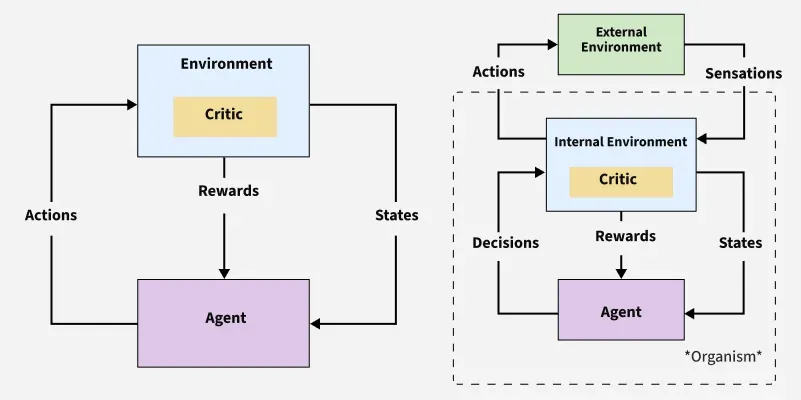
Intrinsic motivation in reinforcement learning (RL) enables agents to generate internal rewards for exploration and skill development when external rewards are sparse or absent. This approach mimics human curiosity, allowing agents to learn efficiently in complex environments without explicit incentive.
Extrinsic vs. intrinsic rewards:
Why it matters: In sparse-reward environments (e.g., robotic navigation), agents rarely receive meaningful feedback. Intrinsic motivation creates dense learning signals by rewarding exploration, uncertainty reduction, or skill mastery.
Biological Analogy: Humans explore driven by inherent curiosity (e.g., a child tinkering with toys). Similarly, RL agents use intrinsic rewards to explore "for its own sake," accelerating learning even without immediate external benefits.
Intrinsic rewards are computed using these principles
Agents self-reward when their predictions fail. For a state st and action at
where:
Rewards maximize information gain or minimize uncertainty:
where
Agents reward competence-building:
where I denotes mutual information. This rewards actions that influence future states.(e.g., a chess AI practicing openings).
Method | Mechanism | Use Case |
|---|---|---|
ICM(Intrinsic Curiosity Module) | Predicts next state; reward = prediction error | Exploration in unfamiliar states |
RND(Random Network Distillation) | Predicts output of a random neural network; reward = prediction error | High-dimensional environments |
Count-Based | Rewards inversely proportional to state visitation frequency | Discrete state spaces |
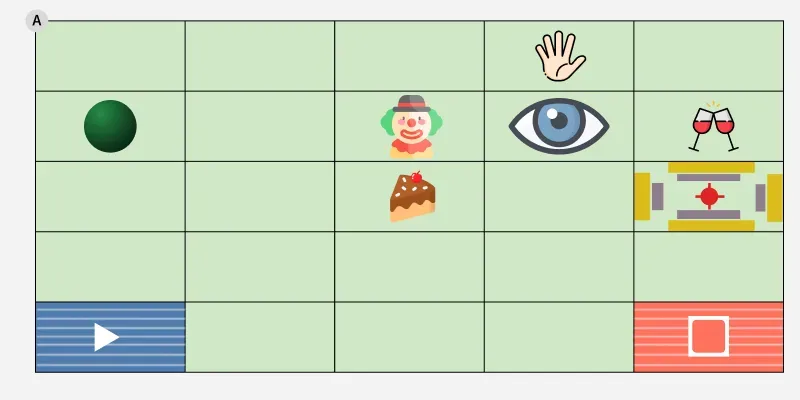
The environment is a playroom containing various interactive objects:
The agent has three effectors: an eye, a hand and a visual marker.
The agent’s sensors report what object is under each effector and if both the eye and hand are on an object, context-specific actions become available (e.g., flicking the switch, kicking the ball).
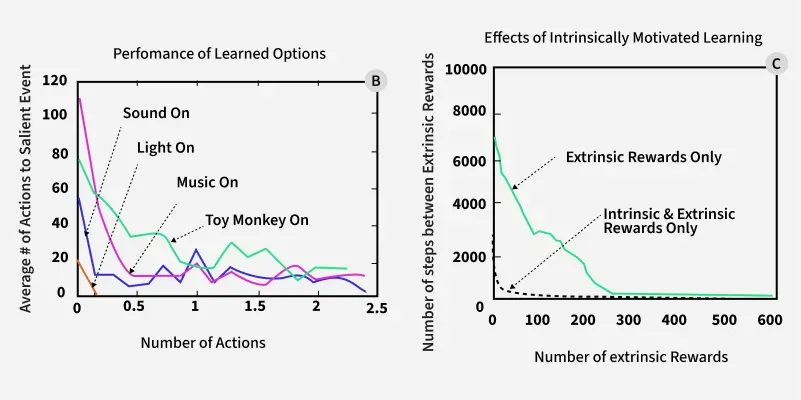
Each time the agent causes an unexpected change (music starts, light turns on, bell rings), it experiences a burst of intrinsic reward.
The first time a salient event occurs (e.g., light turns on), the agent creates:
The agent adds this option to its Skill Knowledge Base (Skill-KB).
The agent is internally motivated to repeat the salient event to maximize its intrinsic reward. Each time the agent achieves the event, it updates:
As the agent’s predictions improve, the intrinsic reward for that event diminishes (the agent gets "bored"). The agent then shifts focus to other unexplored or unpredictable events.
Many complex events (e.g., making the monkey cry out) require a sequence of simpler events (turning on the light, turning on music, ringing the bell). The agent bootstraps:
Over time, the agent develops a hierarchy of options from simple to complex.
The main inference from research and practical applications is that intrinsic motivation enables RL agents to become more autonomous, adaptive and capable of open-ended learning. By rewarding themselves for exploration and skill mastery, agents can learn efficiently even when explicit goals are unclear or feedback is limited. This approach is especially valuable for real-world AI systems that must operate in complex, changing, or poorly defined environments.
{kind=link}
{kind=link}
{kind=link}
{kind=link}