 |
VOOZH | about |
|
VOOZH | about |
tf.keras.layers.GRU is a TensorFlow layer that implements the Gated Recurrent Unit (GRU), a recurrent neural network designed for processing sequential data. It is commonly used in tasks such as speech recognition, machine translation, and time-series forecasting due to its ability to learn patterns across sequences efficiently.
return_sequences, return_state, and dropout for flexible sequence modeling.The tf.keras.layers.GRU layer creates a Gated Recurrent Unit (GRU) for processing sequential data. It provides several parameters to control the layer's behavior, output, and training configuration.
tf.keras.layers.GRU(
units,
activation='tanh',
recurrent_activation='sigmoid',
return_sequences=False,
return_state=False,
dropout=0.0,
recurrent_dropout=0.0,
stateful=False,
unroll=False
)
Parameters
Importing TensorFlow, Keras modules, and NumPy for creating and training the GRU model.
Generating sample sequential data consisting of 100 sequences, each having 10 time steps and 5 features.
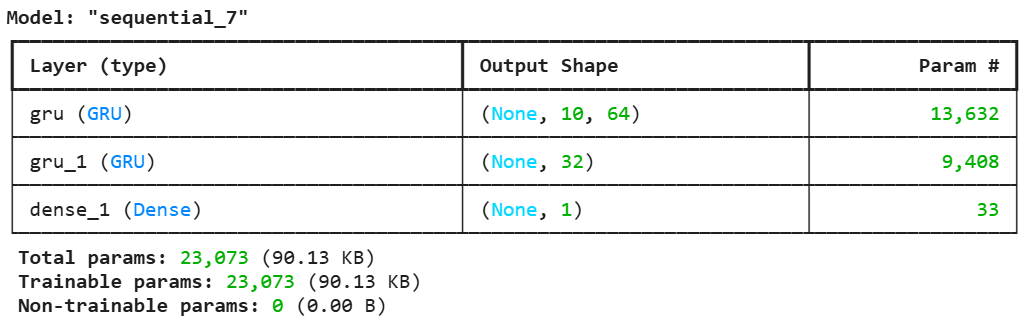
Creating a sequential model with two GRU layers followed by a dense output layer for binary classification.
Output:
Training the model on the generated dataset and monitor the loss and accuracy during training.
Output:
Epoch 1/10
7/7 ━━━━━━━━━━━━━━━━━━━━ 6s 15ms/step - accuracy: 0.5487 - loss: 0.6960
.
.
.
Epoch 9/10
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.6135 - loss: 0.6825
Epoch 10/10
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.6224 - loss: 0.6848
<keras.src.callbacks.history.History at 0x7968ee5983d0>
The return_sequences parameter returns outputs for all time steps, while return_state returns the final hidden state of the GRU layer.
Use the return_sequences and return_state parameters to obtain outputs for all time steps along with the final hidden state.
Output:
(5, 10, 50) (5, 50)
Explanation:
return_sequences, return_state, and dropout for different use cases. {kind=link}
{kind=link}