 |
VOOZH | about |
|
VOOZH | about |
Neural networks have become a cornerstone of modern machine learning, offering unparalleled performance in a wide range of applications. However, their complexity and capacity to learn intricate patterns can also lead to overfitting, where the model becomes too specialized to the training data and fails to generalize well to new, unseen data. Regularization techniques are essential to mitigate this issue, and dropout is one of the most effective and widely used methods.
In this article, we will delve into the concept of dropout, its implementation, and its benefits in training neural networks.
Table of Content
Overfitting occurs when a neural network learns not only the underlying patterns in the training data but also the noise and specific details. This leads to a model that performs well on training data but fails to generalize to new, unseen data. Overfitting is particularly problematic in deep neural networks due to their high capacity to model complex relationships.
Symptoms of Overfitting:
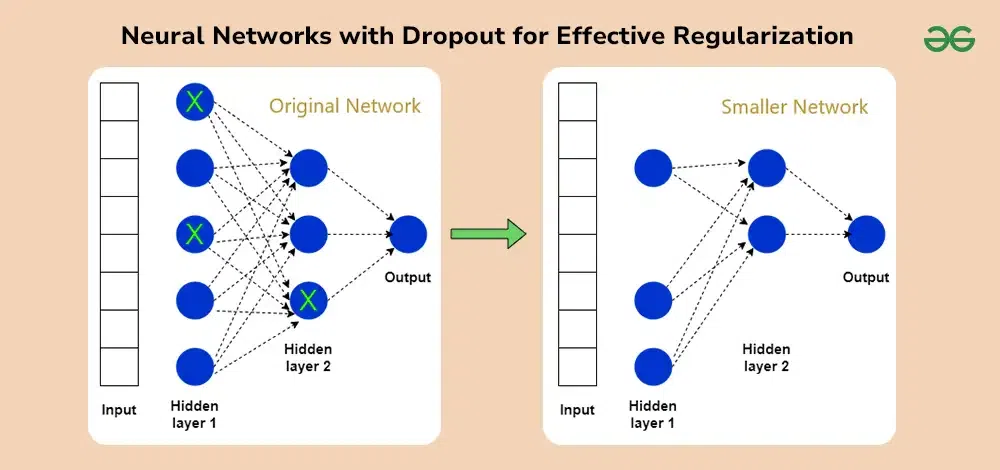
Dropout is a regularization technique introduced by Srivastava et al. in 2014. It involves randomly "dropping out" a fraction of neurons during the training process, effectively creating a sparse network. This randomness prevents the network from becoming overly reliant on specific neurons, thereby reducing overfitting. Dropout Works:
During each training iteration, dropout randomly deactivates a subset of neurons in a layer. The probability of a neuron being dropped is determined by a hyperparameter called the dropout rate.
Mathematics Behind Dropout
if represents the activation layer before dropout and after dropout, we have:
For example, a dropout rate of 0.5 means that each neuron has a 50% chance of being deactivated. The remaining active neurons are scaled up by a factor of to maintain the overall output magnitude.
import tensorflow as tf
# Example of adding dropout in a Keras model
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(10, activation='softmax')
])
1. Training Phase:
2. Testing Phase
By reducing the number of neurons at each iteration while training allows the model to not be dependent on the any particular neuron.
Practical Implementation: In this working demo we will use Tensorflow and utilize its dropout functionality.
For the implementation, we will use MNIST Dataset.
Output:
Epoch 1/20
375/375 - 6s - loss: 0.3889 - accuracy: 0.8799 - val_loss: 0.1412 - val_accuracy: 0.9582 - 6s/epoch - 15ms/step
Epoch 2/20
375/375 - 6s - loss: 0.1781 - accuracy: 0.9461 - val_loss: 0.1059 - val_accuracy: 0.9670 - 6s/epoch - 16ms/step
Epoch 3/20
375/375 - 5s - loss: 0.1370 - accuracy: 0.9589 - val_loss: 0.0993 - val_accuracy: 0.9705 - 5s/epoch - 13ms/step
Epoch 4/20
375/375 - 6s - loss: 0.1121 - accuracy: 0.9656 - val_loss: 0.0864 - val_accuracy: 0.9732 - 6s/epoch - 16ms/step
Epoch 5/20
375/375 - 5s - loss: 0.0998 - accuracy: 0.9686 - val_loss: 0.0802 - val_accuracy: 0.9755 - 5s/epoch - 14ms/step
Epoch 6/20
375/375 - 5s - loss: 0.0866 - accuracy: 0.9725 - val_loss: 0.0815 - val_accuracy: 0.9762 - 5s/epoch - 13ms/step
Epoch 7/20
375/375 - 6s - loss: 0.0806 - accuracy: 0.9748 - val_loss: 0.0824 - val_accuracy: 0.9758 - 6s/epoch - 16ms/step
Epoch 8/20
375/375 - 5s - loss: 0.0719 - accuracy: 0.9770 - val_loss: 0.0733 - val_accuracy: 0.9789 - 5s/epoch - 13ms/step
Epoch 9/20
375/375 - 5s - loss: 0.0727 - accuracy: 0.9773 - val_loss: 0.0783 - val_accuracy: 0.9768 - 5s/epoch - 15ms/step
Epoch 10/20
375/375 - 5s - loss: 0.0649 - accuracy: 0.9785 - val_loss: 0.0733 - val_accuracy: 0.9793 - 5s/epoch - 14ms/step
Epoch 11/20
375/375 - 5s - loss: 0.0617 - accuracy: 0.9805 - val_loss: 0.0767 - val_accuracy: 0.9794 - 5s/epoch - 13ms/step
Epoch 12/20
375/375 - 6s - loss: 0.0616 - accuracy: 0.9802 - val_loss: 0.0755 - val_accuracy: 0.9794 - 6s/epoch - 16ms/step
Epoch 13/20
375/375 - 5s - loss: 0.0569 - accuracy: 0.9815 - val_loss: 0.0705 - val_accuracy: 0.9792 - 5s/epoch - 13ms/step
Epoch 14/20
375/375 - 5s - loss: 0.0545 - accuracy: 0.9824 - val_loss: 0.0698 - val_accuracy: 0.9794 - 5s/epoch - 14ms/step
Epoch 15/20
375/375 - 6s - loss: 0.0495 - accuracy: 0.9836 - val_loss: 0.0737 - val_accuracy: 0.9804 - 6s/epoch - 15ms/step
Epoch 16/20
375/375 - 5s - loss: 0.0501 - accuracy: 0.9845 - val_loss: 0.0758 - val_accuracy: 0.9793 - 5s/epoch - 13ms/step
Epoch 17/20
375/375 - 6s - loss: 0.0500 - accuracy: 0.9832 - val_loss: 0.0685 - val_accuracy: 0.9818 - 6s/epoch - 17ms/step
Epoch 18/20
375/375 - 5s - loss: 0.0503 - accuracy: 0.9831 - val_loss: 0.0673 - val_accuracy: 0.9808 - 5s/epoch - 13ms/step
Epoch 19/20
375/375 - 5s - loss: 0.0428 - accuracy: 0.9862 - val_loss: 0.0722 - val_accuracy: 0.9811 - 5s/epoch - 13ms/step
Epoch 20/20
375/375 - 6s - loss: 0.0444 - accuracy: 0.9858 - val_loss: 0.0706 - val_accuracy: 0.9819 - 6s/epoch - 16ms/step
Output:
Epoch 1/20
375/375 - 6s - loss: 0.2446 - accuracy: 0.9284 - val_loss: 0.1182 - val_accuracy: 0.9625 - 6s/epoch - 16ms/step
Epoch 2/20
375/375 - 5s - loss: 0.0884 - accuracy: 0.9730 - val_loss: 0.0940 - val_accuracy: 0.9706 - 5s/epoch - 12ms/step
Epoch 3/20
375/375 - 7s - loss: 0.0535 - accuracy: 0.9833 - val_loss: 0.0833 - val_accuracy: 0.9772 - 7s/epoch - 19ms/step
Epoch 4/20
375/375 - 4s - loss: 0.0376 - accuracy: 0.9883 - val_loss: 0.0808 - val_accuracy: 0.9749 - 4s/epoch - 12ms/step
Epoch 5/20
375/375 - 4s - loss: 0.0280 - accuracy: 0.9910 - val_loss: 0.0817 - val_accuracy: 0.9777 - 4s/epoch - 12ms/step
Epoch 6/20
375/375 - 6s - loss: 0.0228 - accuracy: 0.9925 - val_loss: 0.0867 - val_accuracy: 0.9783 - 6s/epoch - 16ms/step
Epoch 7/20
375/375 - 4s - loss: 0.0186 - accuracy: 0.9939 - val_loss: 0.0934 - val_accuracy: 0.9782 - 4s/epoch - 12ms/step
Epoch 8/20
375/375 - 5s - loss: 0.0112 - accuracy: 0.9966 - val_loss: 0.1047 - val_accuracy: 0.9743 - 5s/epoch - 13ms/step
Epoch 9/20
375/375 - 5s - loss: 0.0110 - accuracy: 0.9965 - val_loss: 0.1145 - val_accuracy: 0.9747 - 5s/epoch - 14ms/step
Epoch 10/20
375/375 - 4s - loss: 0.0185 - accuracy: 0.9936 - val_loss: 0.1138 - val_accuracy: 0.9747 - 4s/epoch - 12ms/step
Epoch 11/20
375/375 - 5s - loss: 0.0128 - accuracy: 0.9957 - val_loss: 0.1065 - val_accuracy: 0.9781 - 5s/epoch - 14ms/step
Epoch 12/20
375/375 - 5s - loss: 0.0104 - accuracy: 0.9968 - val_loss: 0.1195 - val_accuracy: 0.9747 - 5s/epoch - 13ms/step
Epoch 13/20
375/375 - 4s - loss: 0.0144 - accuracy: 0.9953 - val_loss: 0.1422 - val_accuracy: 0.9716 - 4s/epoch - 12ms/step
Epoch 14/20
375/375 - 6s - loss: 0.0111 - accuracy: 0.9962 - val_loss: 0.1043 - val_accuracy: 0.9781 - 6s/epoch - 16ms/step
Epoch 15/20
375/375 - 4s - loss: 0.0105 - accuracy: 0.9969 - val_loss: 0.1198 - val_accuracy: 0.9774 - 4s/epoch - 12ms/step
Epoch 16/20
375/375 - 6s - loss: 0.0060 - accuracy: 0.9982 - val_loss: 0.1055 - val_accuracy: 0.9799 - 6s/epoch - 15ms/step
Epoch 17/20
375/375 - 6s - loss: 0.0090 - accuracy: 0.9971 - val_loss: 0.1258 - val_accuracy: 0.9773 - 6s/epoch - 16ms/step
Epoch 18/20
375/375 - 4s - loss: 0.0090 - accuracy: 0.9967 - val_loss: 0.1164 - val_accuracy: 0.9787 - 4s/epoch - 12ms/step
Epoch 19/20
375/375 - 5s - loss: 0.0039 - accuracy: 0.9986 - val_loss: 0.1171 - val_accuracy: 0.9806 - 5s/epoch - 15ms/step
Epoch 20/20
375/375 - 5s - loss: 0.0091 - accuracy: 0.9970 - val_loss: 0.1241 - val_accuracy: 0.9787 - 5s/epoch - 13ms/step
Output:
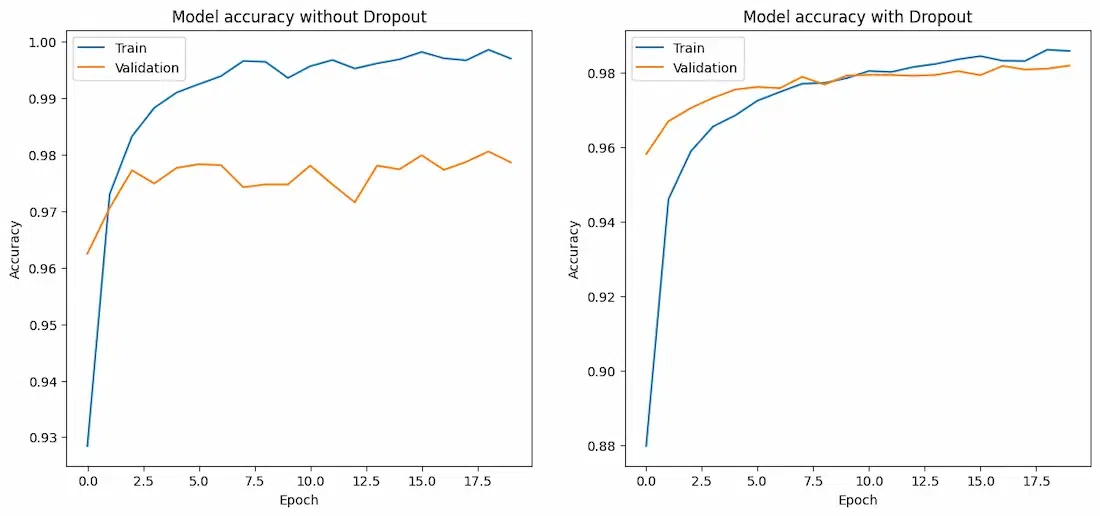
By following these steps, you can observe how Dropout helps in preventing overfitting and improving the generalization of the model.
Dropout offers several benefits that contribute to the improved performance and generalization of neural networks.
Despite its benefits, dropout is not without its challenges. Understanding these drawbacks and how to mitigate them is crucial for effective model training.
To effectively use dropout in neural networks, consider the following tips:
Dropout is a powerful and widely-used regularization technique in deep learning. By randomly deactivating neurons during training, dropout prevents overfitting and improves the generalization of neural networks. While it introduces additional complexity and requires careful hyperparameter tuning, the benefits of dropout make it an essential tool for training robust and effective neural networks.
{kind=link}
{kind=link}
{kind=link}