 |
VOOZH | about |
|
VOOZH | about |
In the expansive field of machine learning, undercomplete autoencoders have carved out a niche as powerful tools for unsupervised learning, especially in dimensionality reduction and feature extraction. These specialized types of neural networks are designed to compress input data into a lower-dimensional space and then reconstruct it back to its original form.
This article explores undercomplete autoencoders from both practical and mathematical perspectives, detailing their structure, operation, applications, and the mathematical principles that govern their functionality.
Table of Content
An undercomplete autoencoder is a type of autoencoder of aims to learn a compressed representation of its input data. It is termed "undercomplete" because it forces the representation to have a lower dimensionality than the input itself, thereby learning to capture only the most essential features.
An undercomplete autoencoder is typically structured into two main components:
The primary goal of training an undercomplete autoencoder is minimizing the difference between the original input and its reconstruction . This is generally achieved using the mean squared error (MSE) loss function:
Minimizing this loss encourages the autoencoder to learn efficient data representations and reconstruction mappings.
The operation of an undercomplete autoencoder involves several key steps:
First we Load the required packages.
The MNIST dataset is loaded and normalized. The images are reshaped to include a channel dimension.
The encoder part compresses the input image into a smaller latent representation using convolutional layers and max-pooling. Also the decoder part reconstructs the original image from the compressed representation using up-sampling and convolutional layers.
The autoencoder is trained using binary crossentropy loss and the Adam optimizer. The training process aims to minimize the reconstruction error.
After training, the autoencoder's performance is evaluated by encoding and decoding test images. The results are displayed to show the original images alongside their reconstructions.
Output:
Epoch 1/50
235/235 [==============================] - 2s 7ms/step - loss: 0.2771 - val_loss: 0.1880
Epoch 2/50
235/235 [==============================] - 1s 5ms/step - loss: 0.1686 - val_loss: 0.1520
Epoch 3/50
235/235 [==============================] - 1s 5ms/step - loss: 0.1428 - val_loss: 0.1322
Epoch 4/50
235/235 [==============================] - 1s 6ms/step - loss: 0.1272 - val_loss: 0.1203
Epoch 5/50
235/235 [==============================] - 1s 5ms/step - loss: 0.1174 - val_loss: 0.1122
Epoch 6/50
235/235 [==============================] - 1s 5ms/step - loss: 0.1104 - val_loss: 0.1062
.
.
.
Epoch 45/50
235/235 [==============================] - 1s 6ms/step - loss: 0.0926 - val_loss: 0.0915
Epoch 46/50
235/235 [==============================] - 1s 6ms/step - loss: 0.0926 - val_loss: 0.0914
Epoch 47/50
235/235 [==============================] - 1s 6ms/step - loss: 0.0926 - val_loss: 0.0914
Epoch 48/50
235/235 [==============================] - 1s 6ms/step - loss: 0.0926 - val_loss: 0.0915
Epoch 49/50
235/235 [==============================] - 1s 5ms/step - loss: 0.0926 - val_loss: 0.0915
Epoch 50/50
235/235 [==============================] - 1s 5ms/step - loss: 0.0926 - val_loss: 0.0914
In the undercomplete version, the bottleneck size (32) is significantly smaller than the input size (784), forcing the network to learn a compressed representation of the data.
Undercomplete autoencoders are versatile and find applications across various domains:
Despite their advantages, undercomplete autoencoders face several challenges:
Undercomplete autoencoders represent a sophisticated approach in the toolkit of machine learning practitioners, capable of extracting valuable insights from vast datasets by focusing on the most impactful features. By compressing and reconstructing data, these networks not only reduce dimensionality but also enhance our understanding and processing of complex datasets. As machine learning continues to evolve, the adaptability and effectiveness of undercomplete autoencoders ensure they remain a valuable asset in addressing diverse data-driven challenges.
{kind=link}
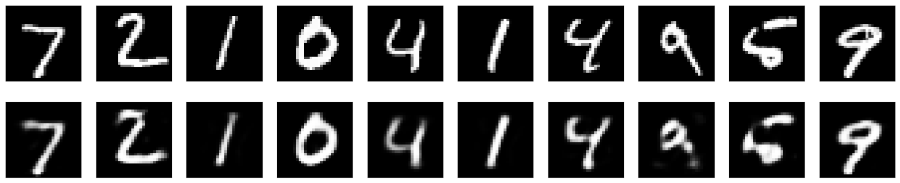{kind=link}