 |
VOOZH | about |
|
VOOZH | about |
Gated Recurrent Units (GRUs) are an advanced type of recurrent neural network designed to efficiently model sequential and time-series data. By using gating mechanisms, GRUs address the vanishing gradient problem common in traditional RNNs, enabling them to capture long-term dependencies with fewer parameters and faster training compared to LSTMs.
Although LSTM are effective at learning long-term dependencies, they have some limitations that can make them less practical in certain scenarios.
GRUs are designed to address the limitations of LSTMs while still capturing long-term dependencies in sequential data.
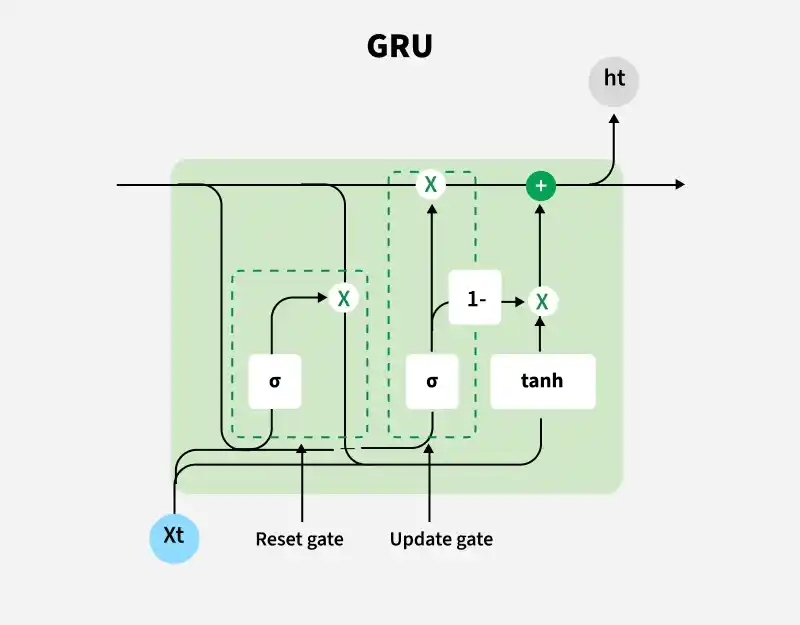
The GRU architecture uses gating mechanisms to efficiently control the flow of information and capture long-term dependencies in sequential data.
The GRU consists of two main gates:
These gates allow GRU to control the flow of information in a more efficient manner compared to traditional RNNs which solely rely on hidden state.
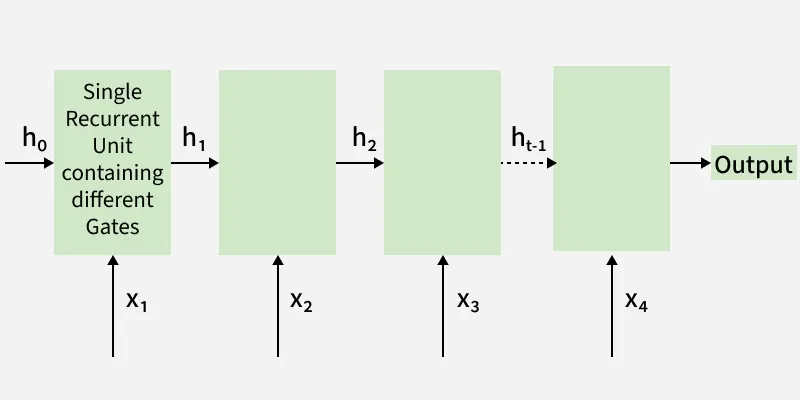
The GRU processes sequences by selectively keeping or forgetting information at each time step. Its update and reset gates work together to efficiently capture long-term dependencies in the data.
1. Reset Gate
The reset gate determines how much of the previous hidden state should be forgotten
controls how much of the past information to ignore when computing the candidate hidden state
The operation represents concatenation of the previous hidden state and the current input
2. Update Gate
The update gate decides how much of the previous hidden state should be carried forward to the current step
where is weight matrix for update gate.
controls the balance between keeping past information and using new candidate information.
3. Candidate Hidden State
The candidate hidden state represents the potential new information for the current step
where is Candidate hidden state
Here we combines selected past information and current input to form the new candidate
4. Final Hidden State
The final hidden state is a combination of the previous hidden state and the candidate hidden state, controlled by the update gate:
The final hidden state is passed to the next step, carrying important information forward in the sequence.
Here we implement GRU in R Programming Language.
We will use the keras library, which provides a high-level API for building and training deep learning models in R. Ensure you have the keras library installed and loaded.
Here we create a simple time series dataset. We will generate a sine wave and use it for training our GRU model.
We will use the keras library to define and compile the GRU model.
Output:
Train the model using the training data.
Output:
Final epoch (plot to see history):
loss: 0.05499
val_loss: 0.04849
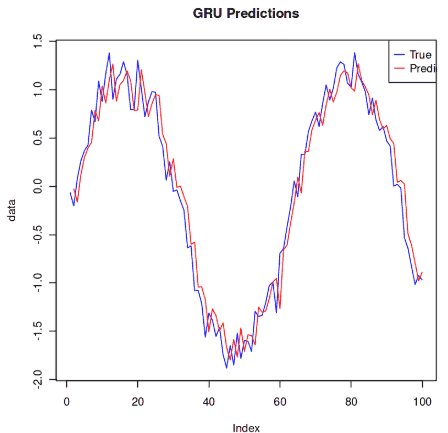
Use the trained model to make predictions.
Output:
Download full code from here
GRUs and Long Short-Term Memory (LSTM) networks are both designed to handle sequential data and long-term dependencies, but they differ in structure and computational efficiency.
Feature | GRU | LSTM |
|---|---|---|
Number of Gates | 2 (Update and Reset) | 3 (Input, Forget, Output) |
Memory Cell | No separate cell state uses hidden state only | Uses separate cell state and hidden state |
Complexity | Simpler, fewer parameters | More complex, more parameters |
Training Speed | Faster due to fewer parameters | Slower due to more gates |
Performance | Often performs better or similar | Can overfit on smaller datasets |
Long-Term Memory Handling | Good, but slightly less flexible | Excellent due to separate cell state |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}