 |
VOOZH | about |
|
VOOZH | about |
Layer Normalization stabilizes and accelerates the training process in deep learning. In typical neural networks, activations of each layer can vary drastically which leads to issues like exploding or vanishing gradients which slow down training. Layer Normalization addresses this by normalizing the output of each layer which helps in ensuring that the activations stay within a stable range.
It works by normalizing the input to each neuron such that the mean activation becomes 0 and the variance becomes 1. Unlike Batch Normalization which normalizes over the batch i.e across all samples in the batch, it normalizes over the features for each individual data point.
Let's consider an example where we have three vectors:
For each input of the layer, Layer Normalization computes the following:
Mean and variance are calculated for each input but instead of across the batch, it’s done for the features (i.e per data point):
where, is the number of features (neurons) in the layer, is the input for each feature and and are the computed mean and variance.
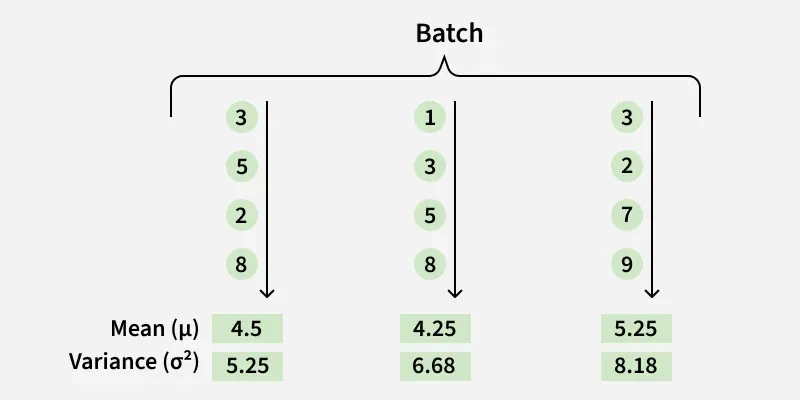
Now, let's compute Mean and Variance for each feature (Per Data Point). For :
Similarly computer for and :
Each feature is then normalized using the formula:
Here is a small constant added for numerical stability.
Now, we will normalize each feature in each vector by subtracting the mean and dividing by the standard deviation (square root of the variance) with a small constant added for numerical stability.
For :
We calculate each normalized value for :
For :
We calculate each normalized value for :
For :
We calculate each normalized value for :
To ensure that the normalized activations can still represent a wide range of values, learnable parameters (scaling) and (shifting) are introduced. Final output is computed as:
This allows the network to scale and shift the normalized activations during training.
In real Layer Normalization, and are not scalars. They are vectors of size H (number of features). Each feature has its own learnable and :
For simplicity, the following example uses scalar and only to show the calculation steps. Here let’s assume and . We can apply this scaling and shifting to the normalized values to get the final output for each vector.
These are the exact normalized values and the final outputs after applying Layer Normalization.
We will be using Pytorch library for its implementation.
Output:
Layer Normalization is commonly used in various deep learning architectures:
Layer normalization is effective in scenarios where Batch Normalization would not be practical such as with small batch sizes or sequential models like RNNs. It helps to ensure a smoother and faster training process which leads to better performance across wide range of applications.
{kind=link}
{kind=link}
{kind=link}