CART (Classification And Regression Tree) in Machine Learning
Last Updated : 4 Dec, 2025
To break a dataset into smaller, meaningful groups, CART (Classification and Regression Tree) is used which builds a decision tree that predicts outcomes for both classification and regression tasks. It works by splitting data based on rules that reduce error at each step.
Uses binary splits at every node.
Simple to understand and interpret.
Works for both numeric and categorical data.
Forms the base of advanced models like Random Forest, Gradient Boosting and XGBoost.
How CART Builds a Decision Tree
CART (Classification and Regression Trees) constructs a decision tree by recursively splitting the dataset based on the feature and threshold that produce the highest reduction in impurity (for classification) or error (for regression)
Check all features and their possible split values.
Compute impurity or error.
Identify the split that gives the maximum reduction in impurity or error.
Step 2: Select the Optimal Split
Compare impurity decrease for all features.
Choose the feature and threshold pair with the best score.
This becomes the splitting rule for the current node.
Step 3: Create Binary Child Nodes
Split the dataset into Left Node (values less than or equal to threshold) and Right Node (values greater than or equal to threshold).
Assign corresponding samples to each child node.
Step 4: Apply Recursive Splitting
Repeat the same process for each child node.
Continue until a stopping condition is met.
CART for Classification
CART is used for classification tasks when the output variable is categorical.
How it Works
Recursively splits the dataset to increase class purity at each step.
Uses Gini Impurity to select the best feature and threshold for splitting.
Continues splitting until a stopping rule is met such as maximum tree depth or minimum required samples.
CART chooses splits that produce the purest possible child nodes.
CART for Regression
CART is used for regression tasks where the output variable is numerical.
How it Works
Splits the data to minimize residual error between actual and predicted values.
Uses Mean Squared Error (MSE) or Residual Sum of Squares (RSS) as the splitting criterion.
Each leaf node stores the mean of the target values within that node, which becomes the prediction for new samples.
This helps CART create a tree that provides the lowest possible prediction error.
Splitting Criteria in CART
CART uses different metrics to choose the best splitting rule depending on whether the problem is a classification or regression task. The goal is to find the split that produces the purest child nodes (for classification) or minimum prediction error (for regression).
Splitting Criteria for Classification
CART uses Gini Impurity to measure how mixed the classes are in a node.
Gini Impurity indicates how likely a randomly chosen sample from the node would be incorrectly classified if it were assigned labels according to class distribution.
Where:
: proportion of class in the node
: number of classes
Gini = 0: Node is completely pure (only one class)
Gini close to 1: Node contains a mix of many classes and is highly impure.
Splitting Criteria for Regression
For regression problems, CART uses Residual Sum of Squares (RSS) or Mean Squared Error (MSE) to find the best split.
Residual Sum of Squares (RSS): RSS measures the total squared difference between actual output values and predicted values.
Where:
: actual value
: predicted value
Mean Squared Error (MSE): MSE is simply RSS divided by the number of samples.
Lower RSS or MSE indicates a better split and CART selects the threshold that minimizes the prediction error in the resulting child nodes.
Pruning in CART
Pruning is used to prevent overfitting by trimming branches of the decision tree that add little or no improvement to model accuracy. It simplifies the tree, improves generalization and reduces model complexity.
Types of Pruning in CART
Cost Complexity Pruning: Removes branches by comparing the trade off between tree accuracy and tree size, keeping only those nodes that significantly improve performance.
Reduced Error Pruning: Eliminates nodes that do not improve the model’s accuracy on a validation dataset, ensuring only beneficial splits remain.
Common Stopping or Pruning Criteria Used in CART
Maximum tree depth reached: The tree stops growing after a predefined maximum depth.
Minimum samples required to split a node: Splitting stops when a node has fewer samples than the minimum required.
No further improvement in impurity: If a split does not reduce impurity or error, CART stops splitting.
Node becomes pure: When all samples belong to one class, no further split is needed.
Hyperparameters in CART
CART provides several hyperparameters to control the tree structure, prevent overfitting and improve model performance. Important hyperparameters include:
max_depth: Controls the maximum depth of the tree, preventing it from growing too deep and overfitting the data.
min_samples_split: Specifies the minimum number of samples required to split an internal node; higher values make the tree more conservative.
min_samples_leaf: Determines the minimum number of samples allowed in a leaf node, helping avoid very small or unstable leaves.
max_features: Defines the number of features to consider while looking for the best split; useful for reducing computation and variance.
criterion: Specifies the function used to evaluate the split gini or entropy for classification and MSE for regression.
Step-By-Step Implementation
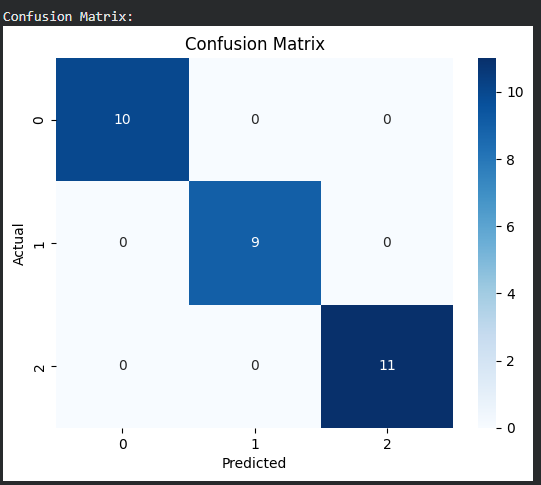
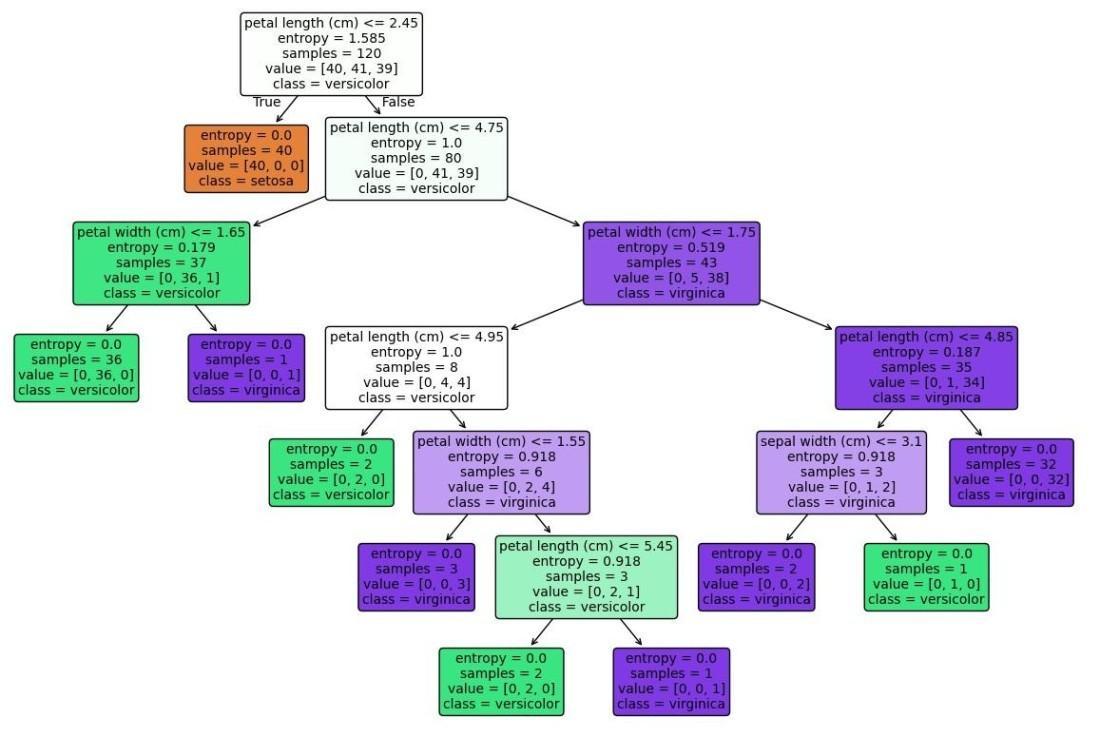
Here we builds and evaluates a Decision Tree (CART) model on the Iris dataset, generating predictions, accuracy metrics and visualizations of the trained tree using Matplotlib and Graphviz.

{kind=link}
{kind=link}
{kind=link}
{kind=link}