 |
VOOZH | about |
|
VOOZH | about |
Agglomerative Clustering is one of the most common hierarchical clustering technique where each data point starts in its own group (cluster) and step by step the closest clusters are joined together until we reach one big cluster. It's a bottom-up approach meaning:
It's used in marketing, biology, education and fraud detection to find natural patterns in data. Let's implement it step by step:
First we will import all the necessary libraries like numpy ,pandas, matplotlib and scikit learn.
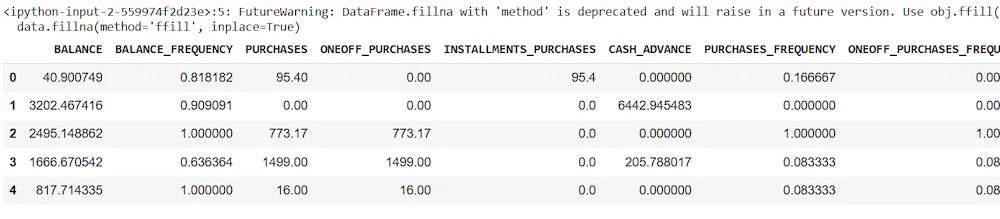
We will now read the .csv file and clean it.
You can download the dataset from here
Output:
We prepare the data so that all features are on the same scale.
We use PCA to reduce many columns features to just 2 so we can easily visualize the data.
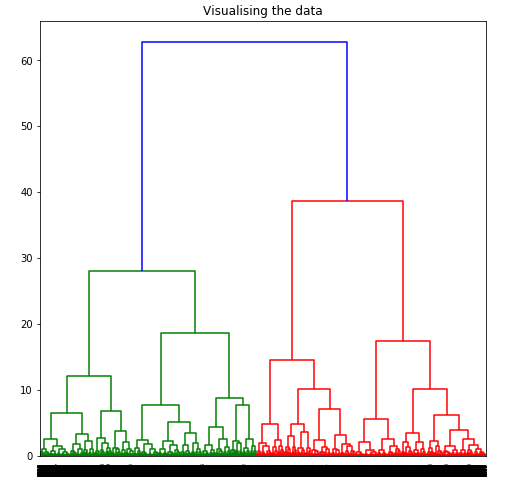
A dendrogramhelps us decide how many clusters to choose. We will use the matplotlib to plot it.
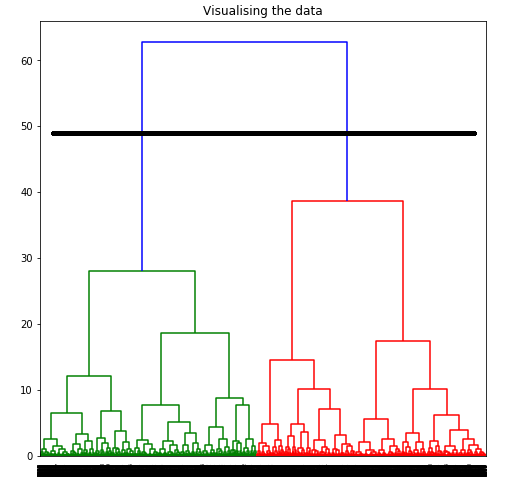
To determine the optimal number of clusters by visualizing the data, imagine all the horizontal lines as being completely horizontal and then after calculating the maximum distance between any two horizontal lines, draw a horizontal line in the maximum distance calculated.
👁 Image
The above image shows that the optimal number of clusters should be 2 for the given data.
Now let’s apply clustering for different values of k (number of clusters). For each value of k we created a clustering model and plot the two PCA components colored by cluster.
Output:
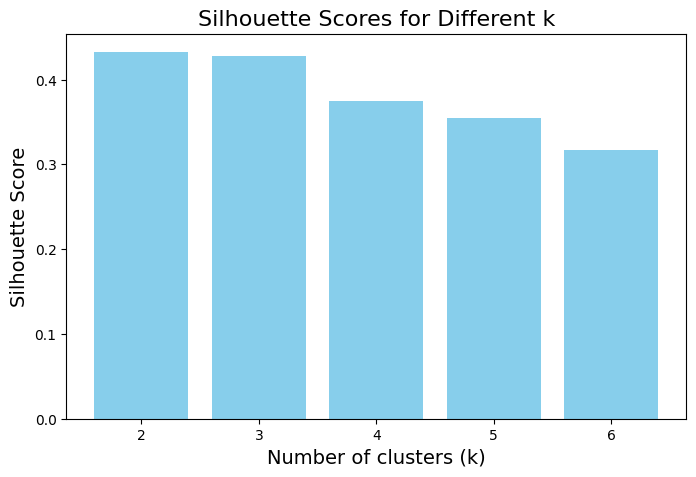
Silhouette score tells us how well the data has been grouped. The Higher the score the better is model.
Output:
As in the above image based on the Silhouette Score and Dendrogram we usually choose the value of k that gives the highest score. In most cases with this dataset the best number of clusters is 2.
To download the complete code: click here
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}