 |
VOOZH | about |
|
VOOZH | about |
Recommender Systems provide personalized suggestions for items that are most relevant to each user by predicting preferences according to user's past choices. They are used in various areas like movies, music, news, search queries, etc. These recommendations are made in two ways:
In this article we’ll build a basic recommender system using Python that recommends movies based on user past preferences.
In this step we will load pandas ,matplotlib and seaborn library. After that we will load user ratings for movies file. Each row in this file shows a user’s rating for a specific movie. To download file click here: .tsv file.
Output:
Now we load another file that matches movie IDs to their titles. This helps us show the actual movie names instead of just numbers. You can download file from here: Movie_Id_Titles.csv.
Output:
We now combine the data about user ratings and movie titles and we can see both the movie names and the ratings for each movie.
Output:
This gives us the average rating for each movie and use to find top-rated movies.
Output:
we can also see how many ratings each movie has. Movies with more ratings are more important when we make recommendations.
Output:
In this step the DataFrame stores the average rating and number of ratings for each movie. We’ll use this later to filter out movies with few ratings.
Output:
We use matplotlib and seaborn to create visual charts that make the data easier to understand.
To Shows how many movies got how many ratings and helps identify popular movies.
Output:
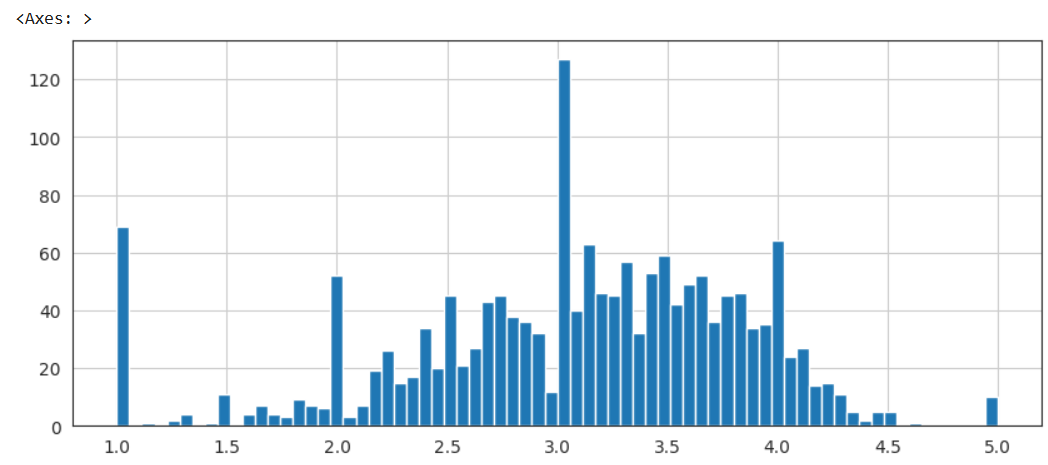
We now show the distribution of average ratings across movies
Output:
We now create a matrix where each row represents a user and each column represents a movie. The values in this matrix are the ratings that users have given to each movie.
Output:
We compare how users rated other movies vs. "Star Wars (1977)".corrwith() calculates correlation with all other movies.
Output:
We create a new DataFrame to store these correlations. Drop any NaN values (movies with no overlapping ratings).
Output:
Join the correlation data with our ratings dataframe. Filter movies that have more than 100 ratings for more reliable recommendations.
Output:
Same process as before now checking for movies similar to “Liar Liar (1997)”.
Output:
We can see that our model is working fine giving recommendations based on user preference.
Get the complete notebook link here:
Colab Link : click here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}