 |
VOOZH | about |
|
VOOZH | about |
Software Engineering is the discipline of applying engineering principles to the design, development, testing, and maintenance of software systems. Understanding the Software Development Life Cycle (SDLC), Software Design & Code Quality, and Testing & Maintenance is essential for both academic and interview preparation.
Top characteristics of software are:
For more details please refer to the following article Characteristics of Software.
The software is used extensively in several domains including hospitals, banks, schools, defense, finance, stock markets, and so on. It can be categorized into different types:
1. Based on Application
2. Based on Copyright
For more details please refer to the following article Classifications of Software.
SDLC stands for Software Development Life Cycle. It is a process followed for software building within a software organization. SDLC consists of a precise plan that describes how to develop, maintain, replace, and enhance specific software. The life cycle defines a method for improving the quality of software and the all-around development process.
Phases of SDLC: Following are the phases of SDLC:
For more details, please refer to the following article Software Development Life Cycle.
Here are the models which is available for the SDLC:
For more details, please refer to the following article Top Software Development Models (SDLC) Models.
The waterfall model is a software development model used in the context of large, complex projects, typically in the field of information technology. It is characterized by a structured, sequential approach to project management and software development.
Phases of Waterfall Model:
Use Case of Waterfall Model
For more details, please refer to the following article Waterfall Model.
The black box test (also known as the conducted test/ closed box test/ opaque box test) is software testing technique. In this technique, tester does not care about the internal knowledge or implementation details but rather focuses on validating the functionality based on the provided specifications or requirements. The name "black box" refers to the idea that the internal workings are hidden from the tester's view.
For more details, please refer to the following article Software Engineering - Black Box Testing.
White Box Testing is a method of analyzing the internal structure, data structures used, internal design, code structure, and behavior of software, as well as functions such as black-box testing. Also called glass-box test or clear box test or structural test.
For more details, please refer to the following article Software Engineering - White Box Testing.
Following are the differences between Alpha and Beta Testing:
Alpha Testing | Beta Testing |
|---|---|
| Alpha testing involves both white box and black box testing. | Beta testing commonly uses black-box testing. |
| Alpha testing is performed by testers who are usually internal employees of the organization. | Beta testing is performed by clients who are not part of the organization. |
| Alpha testing is performed at the developer’s site. | Beta testing is performed at the end-user, the of the product. |
| Reliability and security testing are not checked in alpha testing. | Reliability, security, and robustness are checked during beta testing. |
| Alpha testing ensures the quality of the product before forwarding it to beta testing. | Beta testing also concentrates on the quality of the product but collects the user's time-long input on the product and ensures that the product is ready for real-time users. |
| Alpha testing requires a testing environment or a lab. | Beta testing doesn’t require a testing environment or lab. |
| Alpha testing may require a real-time long execution cycle. | Beta testing requires only a few weeks of execution. |
| Developers can immediately address the critical issues or fixes in alpha testing. | Most of the issues or feedback collected from the beta testing will be implemented in future versions of the product |
For more details, please refer to the following article Alpha Testing and Beta Testing.
Debugging is the process of identifying and resolving errors, or bugs, in a software system. It is an important aspect of software engineering because bugs can cause a software system to malfunction, and can lead to poor performance or incorrect results. Debugging can be a time-consuming and complex task, but it is essential for ensuring that a software system is functioning correctly.
For more details, please refer to the following article What is Debugging?
The Feasibility Study in Software Engineering is a study that analyze whether a proposed software project is practical or not. It early detects the potential issues, analyzes technological possibilities, and determines the project's financial and operational viability. This decreases the chance of project failure that also save time and money.
For more details, please refer to the following article Types of Feasibility Study in Software Project Development article.
A use case diagram is a behavior diagram and visualizes the observable interactions between actors and the system under development. The diagram consists of the system, the related use cases, and actors and relates these to each other:
For more details, please refer to the following article use case diagram.
Here are the difference between Verification and Validation
Verification | Validation |
|---|---|
| Verification is a static practice of verifying documents, design, code, black-box, and programs human-based. | Validation is a dynamic mechanism of validation and testing the actual product. |
| It does not involve executing the code. | It always involves executing the code. |
| It is human-based checking of documents and files. | It is computer-based execution of the program. |
| Verification uses methods like inspections, reviews, walkthroughs, and Desk-checking, etc. | Validation uses methods like black box (functional) testing, gray box testing, and white box (structural) testing, etc. |
| Verification is to check whether the software conforms to specifications. | Validation is to check whether the software meets the customer's expectations and requirements. |
| It can catch errors that validation cannot catch. | It can catch errors that verification cannot catch. |
| Target is requirements specification, application and software architecture, high level, complete design, and database design, etc. | Target is an actual product-a unit, a module, a bent of integrated modules, and an effective final product. |
| Verification is done by QA team to ensure that the software is as per the specifications in the SRS document. | Validation is carried out with the involvement of the testing team |
| It generally comes first done before validation. | It generally follows after verification. |
| It is low-level exercise. | It is a High-Level Exercise. |
For more details, please refer to the following article Software Engineering - Verification and Validation.
A baseline is a measurement that defines the completeness of a phase. After all activities associated with a particular phase are accomplished, the phase is complete and acts as a baseline for next phase.
For more details, please refer to the following article baseline.
Cohesion indicates the relative functional capacity of the module. Aggregation modules need to interact less with other sections of other parts of the program to perform a single task. It can be said that only one coagulation module (ideally) needs to be run. Cohesion is a measurement of the functional strength of a module. A module with high cohesion and low coupling is functionally independent of other modules. Here, functional independence means that a cohesive module performs a single operation or function. The coupling means the overall association between the modules.
Coupling relies on the information delivered through the interface with the complexity of the interface between the modules in which the reference to the section or module was created. High coupling support Low coupling modules assume that there are virtually no other modules. It is exceptionally relevant when both modules exchange a lot of information. The level of coupling between two modules depends on the complexity of the interface.
For more details, please refer to the following article Coupling and cohesion.
The agile SDLC model is a combination of iterative and incremental process models with a focus on process adaptability and customer satisfaction by rapid delivery of working software products. Agile Methods break the product into small incremental builds. Every iteration involves cross-functional teams working simultaneously on various areas like planning, requirements analysis, design, coding, unit testing, and acceptance testing.
Advantages:
For more details, please refer to the following article Software Engineering - Agile Development Models.
Quality Assurance (QA) | Quality Control (QC) |
|---|---|
| It focuses on providing assurance that the quality requested will be achieved. | It focuses on fulfilling the quality requested. |
| It is the technique of managing quality. | It is the technique to verify quality. |
| It does not include the execution of the program. | It always includes the execution of the program. |
| It is a managerial tool. | It is a corrective tool. |
| It is process-oriented. | It is product-oriented. |
| The aim of quality assurance is to prevent defects. | The aim of quality control is to identify and improve the defects. |
| It is a preventive technique. | It is a corrective technique. |
| It is a proactive measure. | It is a reactive measure. |
| It is responsible for the full software development life cycle. | It is responsible for the software testing life cycle. |
| Example: Verification | Example: Validation |
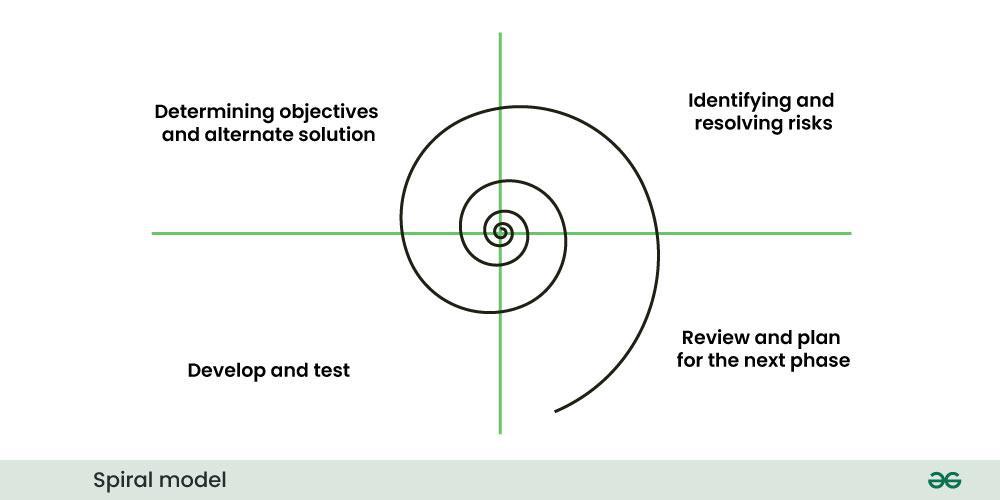
The Spiral Model is a Software Development Life Cycle (SDLC) model that provides a systematic and iterative approach to software development. In its diagrammatic representation, looks like a spiral with many loops. The exact number of loops of the spiral is unknown and can vary from project to project. Each loop of the spiral is called a phase of the software development process.
Following are the disadvantages of spiral model:
For more details, please refer to the following article Software Engineering - Spiral Model.
IBM first proposed the Rapid Application Development or RAD Model in the 1980s. The RAD model is a type of incremental process model in which there is a concise development cycle. The RAD model is used when the requirements are fully understood and the component-based construction approach is adopted.
Following are the limitations of RAD Model:
For more details, please refer to the following article Software Engineering - Rapid Application Development Model (RAD).
Regression testing is defined as a type of software testing that is used to confirm that recent changes to the program or code have not adversely affected existing functionality. Regression testing is just a selection of all or part of the test cases that have been run. These test cases are rerun to ensure that the existing functions work correctly. This test is performed to ensure that new code changes do not have side effects on existing functions. Ensures that after the last code changes are completed, the above code is still valid.
For more details, please refer to the following article regression testing.
CASE stands for Computer-Aided Software Engineering. CASE tools are a set of automated software application programs, which are used to support, accelerate and smoothen the SDLC activities. It is a software package that helps with the design and deployment of information systems. It can record a database design and be quite useful in ensuring design consistency.
Physical DFD and Logical DFD both are the types of DFD (Data Flow Diagram)used to represent how data flows within a system.
Software re-engineering is the process of scanning, modifying, and reconfiguring a system in a new way. The principle of reengineering applied to the software development process is called software reengineering. It has a positive impact on software cost, quality, customer service, and shipping speed. Software reengineering improves software to create it more efficiently and effectively.
For more details please refer to What Is Software Re-Engineering?
Software Reverse Engineering is a process of recovering the design, requirement specifications, and functions of a product from an analysis of its code. It builds a program database and generates information from this. The purpose of reverse engineering is to facilitate maintenance work by improving the understandability of a system and producing the necessary documents for a legacy system.
Reverse Engineering Goals:
For more details, please refer to the following article Software Engineering - Reverse Engineering.
There are some software project estimation techniques available:
For more details, please refer to the following article Software Project Estimation Techniques.
To measure the complexity of software there are some methods in software engineering:
For more details, please refer to the following article complexity of software.
Following are some software analysis and design tools:
For more details, please refer to the following article Computer-Aided Software Engineering(CASE).
Software Requirement Specification (SRS) Format is a complete specification and description of requirements of the software that needs to be fulfilled for successful development of software system. These requirements can be functional as well as non-requirements depending upon the type of requirement. The interaction between different customers and contractors is done because it is necessary to fully understand the needs of customers.
For more details please refer software requirement specification format article.
The highest abstraction level is called Level 0 of DFD. It is also called context-level DFD. It portrays the entire information system as one diagram.
For more details, please refer to the following article DFD.
Function point metrics provide a standardized method for measuring the various functions of a software application. Function point metrics, measure functionality from the user’s point of view, that is, on the basis of what the user requests and receives in return.
For more details, please refer to the following articlefunction point.
The formula to calculate the cyclomatic complexity of a program is:
where,
- e = number of edges
- n = number of vertices
- p = predicates
Example:
A = 10
IF B > C THEN
A = B
ELSE
A = C
ENDIF
Print A
Print B
Print C
Control Flow Graph of the above code:
👁 Cyclomatic ComplexityThe cyclomatic complexity calculated for the above code will be from the control flow graph. The graph shows seven shapes(nodes), and seven lines(edges), hence cyclomatic complexity is 7-7+2 = 2.
The Cyclomatic complexity of a module that has seventeen edges and thirteen nodes = E – N + 2
E = Number of edges, N = Number of nodes
Cyclomatic complexity = 17 – 13 + 2 = 6
A COCOMO model stands for Constructive Cost Model. As with all estimation models, it requires sizing information and accepts it in three forms:
For more details, please refer to the following article Software Engineering - COCOMO Model.
Estimation of software development effort for organic software in the basic COCOMO model is defined as
Organic: Effort = 2.4(KLOC) 1.05 PM
The activities of the software engineering process framework are complemented by a variety of higher-level activities. Umbrella activities typically apply to the entire software project and help the software team manage and control progress, quality, changes, and risks. Common top activities include Software Project Tracking and Control Risk Management, Software Quality Assurance Technical Review Measurement Software Configuration Management Reusability Management Work Product Preparation and Production, etc.
For more details, please refer to the following article Umbrella activities in Software Engineering.
The selection of the best SDLC model is a strategic decision that requires a thorough understanding of the project’s requirements, constraints, and goals. While each model has its strengths and weaknesses, the key is to align the chosen model with the specific characteristics of the project. Being flexible, adaptable, and communicating well are crucial in dealing with the complexities of making software and making sure the final product is good. In the end, the best way to develop software is the one that suits the project's needs and situation the most.
For more details, please refer to the following article Which SDLC Model is Best and Why ?
A block hole concept in the data flow diagram can be defined as "A processing step may have input flows but no output flows". In a black hole, data can only store inbound flows.
With increased expectations for software component quality and the complexity of components, software developers are expected to perform effective testing. In today’s scenario, mutation testing has been used as a fault injection technique to measure test adequacy. Mutation Testing adopts “fault simulation mode”.
A Rayleigh model is used to check software reliability. The Rayleigh model is a parametric model in the sense that it is based on a specific statistical distribution. When the parameters of the statistical distribution are estimated based on the data from a software project, projections about the defect rate of the project can be made based on the model.
To determine an organization’s current state of process maturity, the SEI uses an assessment that results in a five-point grading scheme. The grading scheme determines compliance with a capability maturity model (CMM) that defines key activities required at different levels of process maturity. The SEI approach provides a measure of the global effectiveness of a company's software engineering practices and establishes five process maturity levels that are defined in the following manner:
For more details, please refer to the following article CMM.
The software does not wear out in the traditional sense of the term, but the software does tend to deteriorate as it evolves because Multiple change requests introduce errors in component interactions. Unlike hardware, software doesn’t physically wear out. However, it tends to deteriorate as it evolves because every time new features or updates are added, there's a chance of introducing new bugs or compatibility issues. Over time, multiple changes can cause different parts of the software to interact in unexpected ways, making it harder to maintain. If these issues aren't managed properly, the software becomes more complex and prone to failure, which affects its performance and reliability.
The type and size of the software, the experience of use for reference to predecessors, difficulty level to obtain users’ needs, development techniques and tools, the situation of the development team, development risks, the software development methods should be kept in mind. It is an important prerequisite to ensure the success of software development that designing a reasonable and suitable software development plan.
Adaptive maintenance defines as modifications and updating when the customers need the product to run on new platforms, on new operating systems, or when they need the product to interface with new hardware and software.
The full form of WBS is Work Breakdown Structure. Its Work Breakdown Structure includes dividing a large and complex project into simpler, manageable, and independent tasks. For constructing a work breakdown structure, each node is recursively decomposed into smaller sub-activities, until at the leaf level, the activities become undividable and independent. A WBS works on a top-down approach.
For more detail please refer Work breakdown structure article.
Estimation of the size of the software is an essential part of Software Project Management. It helps the project manager to further predict the effort and time which will be needed to build the project. Various measures are used in project size estimation. Some of these are:
Concurrency refers to a system's ability to execute numerous tasks or processes at the same time, ostensibly concurrently. It is a wider concept that includes the idea of completing many jobs in concurrent intervals. In a concurrent system, tasks can begin, run, and finish in overlapping time frames, increasing overall system efficiency and responsiveness. There are many programming language available that support concurrency using unthreading example Java, C++ etc.
Modular programming makes your code easier to read by dividing it into functions that only deal with one part of the overall functionality. When compared to monolithic code, it can make your files significantly smaller and easier to read.
Clean room software engineering is a software development approach to producing quality software. In clean room software engineering, an efficient and good quality software product is delivered to the client as QA (Quality Assurance) is performed each and every phase of software development.
DLL refers to Dynamic Link Library, and EXE is an executable. An EXE assembly can execute in its own address space, whereas a DLL cannot. It does not have its own address space, therefore it must run within a host and requires a consumer to invoke it.
To do well in interviews, you need to understand core concepts, Software Development Models, Software Project Management, Software metrics, Software requirements, Software Configuration, Quality, Design and Maintenance.
1. Core Concepts:Classification of Software, Software Evolution, Extreme Programming (XP), Agile Development Models, User Interface Design, COCOMO Mode, CMM, Quasi renewal processes, Cyclomatic Complexity, Requirements Elicitation.
2. Advanced Topics:Software Quality, Software Configuration Management, Six Sigma, Software Reliability, Debugging, Software Maintenance, Cohesion vs Coupling, Alpha Testing vs Beta Testing, Selenium.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}