 |
VOOZH | about |
|
VOOZH | about |
Duplicate records can be found in SQL by using the GROUP BY and HAVING clauses along with the COUNT() function. These tools help group similar values and check how many times they appear in a table. They help in:
Syntax:
SELECT column1, column2, ..., COUNT(*)
FROM table_name
GROUP BY column1, column2, ...
HAVING COUNT(*) > 1;
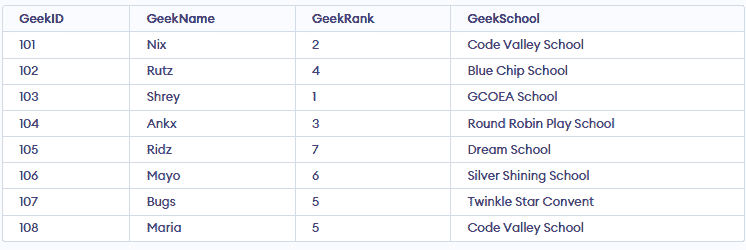
Let’s create a table to find duplicate records in a table using SQL. We will use the GROUP BY and HAVING clauses with the COUNT() function to identify duplicates.
👁 Screenshot-In the above table, we can see there are 2 records with the same geek rank of 5. GeekID 107 and GeekID 108 are having the same rank of 5. Now we need to find this duplication using SQL Query.
Query:
SELECT GeekRank, COUNT(*) AS DuplicateRanks
FROM Geeks
GROUP BY GeekRank
HAVING COUNT(*) > 1;
Output:
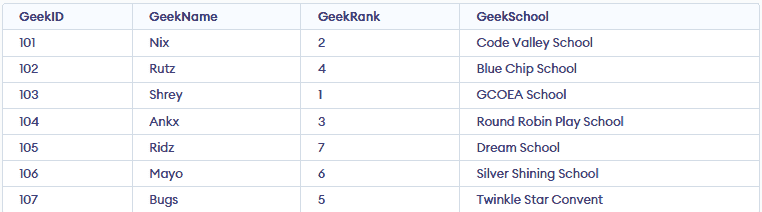
👁 ScreenshotOnce duplicates are identified, you can remove them using the DELETE statement. However, ensure we retain one copy of the duplicate record if needed to preserve important data. This approach helps maintain data integrity while removing redundancy.
Query:
DELETE FROM Geeks
WHERE GeekID NOT IN (
SELECT * FROM (
SELECT MIN(GeekID)
FROM Geeks
GROUP BY GeekRank
) AS temp
);
Output:
👁 Screenshot{kind=link}
{kind=link}
{kind=link}
{kind=link}