 |
VOOZH | about |
|
VOOZH | about |
SQL (Structured Query Language) is the standard language used with relational DBMSs to define schemas (DDL), manipulate and query data (DML/DQL) and optimize access so it’s a core skill for developers, data analysts and DBAs and a frequent interview focus. SQL covers:
| CHAR | VARCHAR2 |
|---|---|
| CHAR stores fixed-length character data. | VARCHAR2 stores variable-length character data. |
| It pads unused space with trailing spaces. | It does not pad unused space, saving storage. |
A view is a virtual table created from a SELECT query that displays data from one or more tables without storing it, helping simplify queries and improve security.
The UNIQUE constraint ensures that all values in a column (or combination of columns) are distinct. This prevents duplicate values and helps maintain data integrity.
A composite primary key uses two or more columns together to uniquely identify each row when one column alone isn’t sufficient.
WHERE and HAVING clausesWHERE filters individual rows before grouping or aggregation, so it can’t use aggregate functions like SUM or COUNT; it’s best for narrowing raw data early (e.g., a date range or status).
HAVING filters the resulting groups after GROUP BY, so it’s meant for conditions on aggregates (e.g., groups with totals above a threshold).
Example:
SELECT customer_id, COUNT(*) AS orders_2025
FROM orders
WHERE order_date >= '2025-01-01' AND order_date < '2026-01-01'
GROUP BY customer_id
HAVING COUNT(*) > 5;
SQL joins combine rows from two tables based on a matching condition (typically keys) to answer questions that span both tables.
NULL.NULL when absent.NULL where a counterpart is missing.PRIMARY KEY and how it differs from a UNIQUE keyA PRIMARY KEY uniquely identifies each row in a table: it combines UNIQUE + NOT NULL, there can be only one per table (though it can be composite across multiple columns) and it’s the default target for foreign keys.
A UNIQUE key also enforces uniqueness, but doesn’t require NOT NULL and you can have many UNIQUE constraints per table.
A CTE (Common Table Expression) is a temporary, named result set defined with WITH that exists only for the duration of a single statement. You use CTEs to break complex logic into steps, avoid repeating the same subquery, improve readability/maintenance, enable recursion (e.g., org charts, folder trees) and make debugging easier.
Normalization organizes relational data to minimize redundancy and prevent update/insert/delete anomalies by splitting tables based on dependencies while preserving meaning.
UNION and UNION ALL?| UNION | UNION ALL |
|---|---|
| It combines results from multiple SELECT queries and removes duplicate rows. | It combines results from multiple SELECT queries and keeps all duplicate rows. |
| It performs DISTINCT operation, so it can be slower. | It does not remove duplicates, so it is faster. |
| It is used when unique results are required. | It is used when all results, including duplicates, are needed. |
A clustered index stores table rows in the physical order of the index key (the data pages are the index), so you can have only one; it’s ideal for range scans and primary-key lookups.
order_id, order_date).A non-clustered index is a separate structure (key → row locator) and you can have many; it accelerates specific filters, joins and sorts without changing the table’s row order.
WHERE email=?).INCLUDEd columns.SQL supports pattern matching mainly with LIKE (and NOT LIKE) using wildcards—% for any-length string and _ for a single character.
PostgreSQL has case-insensitive ILIKE, SIMILAR TO and regex operators (~, ~*), MySQL/SQLite offer REGEXP/REGEXP_LIKE and all allow an optional ESCAPE clause to treat % or _ as literals.
Use a window (analytic) function: compute SUM(amount) over rows of the same product, ordered by time, accumulating from the start up to the current row. This keeps row detail while adding a running total.
SELECT
product_id,
sale_date,
amount,
SUM(amount) OVER (
PARTITION BY product_id
ORDER BY sale_date, sale_id
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS running_total
FROM sales;
A correlated subquery is a subquery that depends on the current row of the outer query—i.e., it references columns from the outer query and is re-evaluated for each outer row.
Example use case employees paid above their own department’s average:
SELECT e.employee_id, e.name, e.salary, e.department_id
FROM employees e
WHERE e.salary >
(SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e.department_id);
EXISTS checks whether a correlated subquery returns at least one row; NOT EXISTS checks that it returns none. They return boolean and stop at the first match, ignoring what the subquery selects. IN compares a value against a list/set (literal list or subquery output).
EXISTS/NOT EXISTS use a correlated subquery and are robust with NULLsNOT IN is NULL-sensitive if the subquery can yield NULL, NOT IN may return no rows (unknown comparison), so prefer NOT EXISTSEXISTS often wins for large subqueries with indexes; IN is fine for small, deduplicated lists.An anti-join returns rows from one table (the “left”) that have no matching rows in another table (the “right”) based on a join condition—i.e., “in A but not in B.” It’s commonly expressed as a LEFT JOIN followed by WHERE right.pk IS NULL or with a semi-join style predicate like NOT EXISTS.
| RANK() | DENSE_RANK() | ROW_NUMBER() |
|---|---|---|
| It assigns the same rank to equal values and leaves gaps in ranking. | It assigns the same rank to equal values without leaving gaps. | It assigns a unique number to each row regardless of ties. |
| It is useful when ranking with competition-style results. | It is useful when continuous ranking without gaps is needed. | It is useful when you need a unique sequence number for each row. |
LAG and LEAD are window functions that let you look at values from previous (LAG) or next (LEAD) rows in the same result set without self-joins. They’re used for comparisons across rows e.g., changes from yesterday to today, detecting trends or filling forward/backward values
A CROSS JOIN returns the cartesian product of two tables every row from A paired with every row from B so the result size is rows(A) × rows(B) and it doesn’t use a join condition
An INNER JOIN returns only the rows where the specified join condition matches between the two tables (e.g., matching keys), so its result is a filtered subset, not every combination
A foreign key (FK) is a column (or set of columns) in a child table that references a primary/unique key in a parent table to ensure the child’s values actually exist in the parent. This enforces referential integrity by preventing actions that would create “orphan” rows.
UNION, INTERSECT and EXCEPT are SQL set operations that combine results from two queries with the same number of columns and compatible data types. UNION returns the distinct union of both result sets (removes duplicates).
MINUS in Oracle) returns rows in the first query that aren’t in the second.To optimize a slow query,
EXPLAIN to find slow partsSELECT *A query is a SQL statement used to retrieve, update or manipulate data in a database. The most common type of query is a SELECT statement, which fetches data from one or more tables based on specified conditions.
A subquery is a query nested within another query. It is often used in the WHERE clause to filter data based on the results of another query, making it easier to handle complex conditions.
Database partitioning is the practice of splitting a large table (and its indexes) into smaller, more manageable pieces called partitions while keeping it logically a single table.This improves query performance (partition pruning scans only relevant partitions), eases maintenance (backup/reindex/archiving per partition) and enhances availability.
The primary defense against SQL injection is to use parameterized queries (prepared statements) everywhere never build SQL with string concatenation. Combine this with allow-list input validation (e.g., only digits for IDs), least-privilege DB accounts (no DROP, limited schema access) and safe stored procedures that don’t assemble dynamic SQL.
SQL commands are broadly classified into:
The DEFAULT constraint assigns a default value to a column when no value is provided during an INSERT operation. This helps maintain consistent data and simplifies data entry.
Denormalization is the process of combining normalized tables into larger tables for performance reasons. It is used when complex queries and joins slow down data retrieval and the performance benefits outweigh the drawbacks of redundancy.
|| (Oracle, PostgreSQL) or + (SQL Server) to combine strings.The GROUP BY clause is used to arrange identical data into groups. It is typically used with aggregate functions (such as COUNT, SUM, AVG) to perform calculations on each group rather than on the entire dataset.
Aggregate functions perform calculations on a set of values and return a single value. Common aggregate functions include:
Indexes are database objects that improve query performance by allowing faster retrieval of rows. They function like a book’s index, making it quicker to find specific data without scanning the entire table. However, indexes require additional storage and can slightly slow down data modification operations. Types of Indexes:
| DELETE | TRUNCATE |
|---|---|
| Removes rows one by one, logs each deletion, allows rollback and supports WHERE clause. | Removes all rows at once, minimal logging, faster, no rollback and no WHERE clause. |
| It is a DML command. | It is a DDL command. |
| SQL Databases | NoSQL Databases |
|---|---|
| They use structured tables with rows and columns. | They use flexible, schema-less structures like key-value or documents. |
| They follow a fixed schema. | They do not require a fixed schema. |
| They support ACID properties for reliable transactions. | They often prioritize performance and scalability over strict consistency. |
| They are best for structured and stable data. | They are suitable for large, fast-changing and unstructured data. |
| They scale vertically (by increasing resources). | They scale horizontally (by adding more servers). |
Common constraints include:
A cursor is a database object used to retrieve, manipulate and traverse through rows in a result set one row at a time. Cursors are helpful when performing operations that must be processed sequentially rather than in a set-based manner.
Types of Cursors (SQL Server):
A trigger is a set of SQL statements that automatically execute in response to certain events on a table, such as INSERT, UPDATE, or DELETE. Triggers help maintain data consistency, enforce business rules and implement complex integrity constraints.
The SELECT statement retrieves data from one or more tables. It is the most commonly used command in SQL, allowing users to filter, sort and display data based on specific criteria.
ORDER BY sorts the result set of a query in ascending or descending order based on one or more columns.
A table is a structured collection of related data organized into rows and columns. Columns define the type of data stored, while rows contain individual records.
NULL represents a missing or unknown value. It is different from zero or an empty string. NULL values indicate that the data is not available or applicable.
A stored procedure is a precompiled set of SQL statements stored in the database. It can take input parameters, perform logic and queries and return output values or result sets. Stored procedures improve performance and maintainability by centralizing business logic.
| DDL (Data Definition Language) | DML (Data Manipulation Language) |
|---|---|
| It is used to define and modify the structure of the database. | It is used to manage and manipulate the data inside the database. |
| It works on tables, schemas and database objects. | It works on the rows stored in tables. |
| It includes commands like CREATE, ALTER and DROP. | It includes commands like INSERT, UPDATE and DELETE. |
| It changes the overall structure of the database. | It changes the actual data present in the database. |
The ALTER command is used to modify the structure of an existing database object. This command is essential for adapting our database schema as requirements evolve.
Data integrity refers to the accuracy, consistency and reliability of the data stored in the database. SQL databases maintain data integrity through several mechanisms:
NOT NULL ensures a column cannot have missing values, FOREIGN KEY ensures a valid relationship between tables and UNIQUE ensures no duplicate values.ON DELETE CASCADE and ON UPDATE CASCADE, automatically updating or removing related rows.The CASE statement is SQL’s way of implementing conditional logic in queries. It evaluates conditions and returns a value based on the first condition that evaluates to true. If no condition is met, it can return a default value using the ELSE clause.
Example:
SELECT ID,
CASE
WHEN Salary > 100000 THEN 'High'
WHEN Salary BETWEEN 50000 AND 100000 THEN 'Medium'
ELSE 'Low'
END AS SalaryLevel
FROM Employees;
The COALESCE function returns the first non-NULL value from a list of expressions. It’s commonly used to provide default values or handle missing data gracefully.
Example:
SELECT COALESCE(NULL, NULL, 'Default Value') AS Result;| COUNT() | SUM() |
|---|---|
| Counts number of rows or non-NULL values | Adds all numeric values in a column |
Query: SELECT COUNT(*) FROM Orders;<br> | Query: SELECT SUM(TotalAmount) FROM Orders; |
| NVL() | NVL2() |
|---|---|
| Replaces NULL with a given value | Returns one value if NOT NULL, another if NULL |
| Takes 2 arguments | Takes 3 arguments |
SELECT NVL(Salary, 0) FROM Employees; | SELECT NVL2(Salary, 'Has Salary', 'No Salary') FROM Employees; |
Scalar functions operate on individual values and return a single value as a result. They are often used for formatting or converting data. Common examples include:
COUNT(column) ignores NULL values and only counts non-NULL entries.COUNT(*) counts all rows, including those with NULL values in columns.Example:
SELECT Name, ROW_NUMBER() OVER (ORDER BY Salary DESC) AS RowNum
FROM Employees;
Window functions perform calculations across a group of related rows while keeping each row separate. They are used for tasks like running totals, rankings and moving averages.
SELECT Name, Salary,
SUM(Salary) OVER (ORDER BY Salary) AS RunningTotal
FROM Employees;
| Index | Key |
|---|---|
| Used to improve data retrieval speed | Used to enforce data integrity and relationships |
| Physical database object | Logical concept |
| Does not ensure uniqueness (can be non-unique) | Ensures uniqueness (e.g., Primary Key) |
| Helps in faster searching of data | Defines relationships (e.g., Foreign Key) |
Indexing helps the database quickly find data without scanning the whole table, reducing time and improving query performance.
Example:
CREATE INDEX idx_lastname ON Employees(LastName);
SELECT * FROM Employees WHERE LastName = 'Smith';
The index on LastName lets the database quickly find all rows matching ‘Smith’ without scanning every record.
Advantages
Disadvantages:
Temporary tables are tables that exist only for the duration of a session or a transaction. They are useful for storing intermediate results, simplifying complex queries, or performing operations on subsets of data without modifying the main tables.
1. Local Temporary Tables:
# (e.g., #TempTable).2. Global Temporary Tables:
## (e.g., ##GlobalTempTable).Example:
CREATE TABLE #TempResults (ID INT, Value VARCHAR(50));
INSERT INTO #TempResults VALUES (1, 'Test');
SELECT * FROM #TempResults;
Standard View:
Materialized View:
In Oracle/Postgres, you use:
REFRESH MATERIALIZED VIEW my_view;A sequence is a database object that generates a series of unique numeric values. It’s often used to produce unique identifiers for primary keys or other columns requiring sequential values.
Example:
CREATE SEQUENCE seq_emp_id START WITH 1 INCREMENT BY 1;
SELECT NEXT VALUE FOR seq_emp_id; -- Returns 1
SELECT NEXT VALUE FOR seq_emp_id; -- Returns 2
Constraints enforce rules that the data must follow, preventing invalid or inconsistent data from being entered:
CHECK (Salary > 0)).Local Temporary Table:
# (e.g., #TempTable).Global Temporary Table:
Example:
CREATE TABLE #LocalTemp (ID INT);
CREATE TABLE ##GlobalTemp (ID INT);
The MERGE statement combines multiple operations INSERT, UPDATE and DELETE into one. It is used to synchronize two tables by:
Example:
MERGE INTO TargetTable T
USING SourceTable S
ON T.ID = S.ID
WHEN MATCHED THEN
UPDATE SET T.Value = S.Value
WHEN NOT MATCHED THEN
INSERT (ID, Value) VALUES (S.ID, S.Value);
1. GROUP BY: Aggregate rows to eliminate duplicates
SELECT Column1, MAX(Column2)
FROM TableName
GROUP BY Column1;
2. ROW_NUMBER(): Assign a unique number to each row and filter by that
WITH CTE AS (
SELECT Column1, Column2, ROW_NUMBER() OVER (PARTITION BY Column1 ORDER BY Column2) AS RowNum
FROM TableName
)
SELECT * FROM CTE WHERE RowNum = 1;
ACID is an acronym that stands for Atomicity, Consistency, Isolation and Durability, four key properties that ensure database transactions are processed reliably.
1. Atomicity:
2. Consistency:
3. Isolation:
4. Durability:
Isolation levels define the extent to which the operations in one transaction are isolated from those in other transactions. They are critical for managing concurrency and ensuring data integrity. Common isolation levels include:
1. Read Uncommitted:
2. Read Committed:
3. Repeatable Read:
4. Serializable:
Example:
SELECT *
FROM Orders WITH (NOLOCK);This query fetches data from theOrderstable without waiting for other transactions to release their locks.
A deadlock is a situation where two or more transactions are waiting for each other to release resources, creating a cycle that prevents any of them from proceeding.
1. Deadlock detection and retry:
2. Reducing lock contention:
3. Using proper isolation levels:
4. Consistent ordering of resource access:
A database snapshot is a read-only, static view of a database at a specific point in time.
Example:
CREATE DATABASE MySnapshot ON
(
NAME = MyDatabase_Data,
FILENAME = 'C:\Snapshots\MyDatabase_Snapshot.ss'
)
AS SNAPSHOT OF MyDatabase;
| OLTP (Online Transaction Processing) | OLAP (Online Analytical Processing) |
|---|---|
| Handles simple, frequent transactions | Handles complex queries and data analysis |
| Optimized for fast read and write operations | Optimized for read-heavy workloads and aggregation |
| Uses normalized schema for data consistency | Uses denormalized schema (star/snowflake) |
| Example: E-commerce, banking systems | Example: Data warehousing, business intelligence |
1. Live Lock
2. Deadlock
The EXCEPT operator is used to return rows from one query’s result set that are not present in another query’s result set. It effectively performs a set difference, showing only the data that is unique to the first query.
Example:
SELECT ProductID FROM ProductsSold
EXCEPT
SELECT ProductID FROM ProductsReturned;
Use Case:
Performance Considerations:
Dynamic SQL is SQL code that is constructed and executed at runtime rather than being fully defined and static. In SQL Server: Use sp_executesql or EXEC. In other databases: Concatenate query strings and execute them using the respective command for the database platform.
Syntax:
DECLARE @sql NVARCHAR(MAX)
SET @sql = 'SELECT * FROM ' + @TableName
EXEC sp_executesql @sql;
Advantages:
Risks:
| Horizontal Partitioning | Vertical Partitioning |
|---|---|
| Divides rows of a table based on column values | Divides columns of a table into separate parts |
| Data is split row-wise (same columns, different rows) | Data is split column-wise (different columns) |
| Improves performance by reducing number of rows scanned | Improves performance by separating frequently and rarely used data |
| Example: Table divided by region or year | Example: Large text columns stored separately |
1. Indexing Strategy:
2. Index Types:
3. Partitioned Indexes:
4. Maintenance Overhead:
5. Monitoring and Tuning:
| Sharding | Partitioning |
|---|---|
| Splits database into multiple independent databases | Splits a table into parts within the same database |
| Used for horizontal scaling across servers | Used for better performance and data management |
| Data is stored on different servers | Data stays in one database |
| Example: Database divided by region | Example: Table divided by year |
1. Write Simple, Clear Queries:
2. Filter Data Early:
3. **Avoid SELECT *:
4. Use Indexes Wisely:
5. Leverage Query Execution Plans:
6. Use Appropriate Join Types:
7. Break Down Complex Queries:
8. Optimize Aggregations:
9. Monitor Performance Regularly:
1. Use Execution Plans:
Review the execution plan of queries to understand how the database is retrieving data, which indexes are being used and where potential bottlenecks exist.
2. Analyze Wait Statistics:
Identify where queries are waiting, such as on locks, I/O, or CPU, to pinpoint the cause of slowdowns.
3. Leverage Built-in Monitoring Tools:
EXPLAIN, SHOW PROFILE and the Performance Schema.EXPLAIN (ANALYZE), pg_stat_statements and log-based monitoring.4. Set Up Alerts and Baselines:
5. Continuous Query Tuning:
1. Indexing
2. Denormalization
Advantages:
Disadvantages:
SQL handles recursive queries using Common Table Expressions (CTEs). A recursive CTE repeatedly references itself to process hierarchical or tree-structured data.
Key Components:
Example:
WITH RecursiveCTE (ID, ParentID, Depth) AS (
SELECT ID, ParentID, 1 AS Depth
FROM Categories
WHERE ParentID IS NULL
UNION ALL
SELECT c.ID, c.ParentID, r.Depth + 1
FROM Categories c
INNER JOIN RecursiveCTE r
ON c.ParentID = r.ID
)
SELECT * FROM RecursiveCTE;
| Transactional Queries | Analytical Queries |
|---|---|
| They focus on short, day-to-day operations like INSERT, UPDATE and DELETE. | They focus on complex analysis, aggregations and data transformations. |
| They are optimized for high speed and quick response (low latency). | They process large volumes of data and are usually read-heavy. |
| They are mainly used in OLTP systems for routine operations. | They are mainly used in OLAP systems for analysis and reporting. |
| They help maintain data integrity in regular operations. | They help in decision-making by providing insights from data. |
The PIVOT operator transforms rows into columns, making it easier to summarize or rearrange data for reporting.
Example:
Converting a dataset that lists monthly sales into a format that displays each month as a separate column.
SELECT ProductID, [2021], [2022]
FROM (
SELECT ProductID, YEAR(SaleDate) AS SaleYear, Amount
FROM Sales
) AS Source
PIVOT (
SUM(Amount)
FOR SaleYear IN ([2021], [2022])
) AS PivotTable;
| Bitmap Index | B-tree Index |
|---|---|
| It uses bitmaps (arrays of bits) to represent data. | It uses a balanced tree structure to store data in sorted order. |
| It is suitable for low-cardinality columns (e.g., gender, yes/no). | It is suitable for high-cardinality columns (e.g., IDs, large ranges). |
| It is efficient for logical operations like AND, OR, NOT. | It is efficient for range-based queries. |
| It is best for filtering and boolean conditions. | It is best for searching and sorting large datasets. |
| Blocking | Deadlocking |
|---|---|
| One transaction waits because another holds the lock | Two or more transactions wait for each other (circular wait) |
| Resolves automatically after lock release | Needs detection and rollback to resolve |
Managers :
👁 Screenshot-2026-02-09-113921Query:
DELETE M1👁 Screenshot-2026-02-09-114310
From managers M1, managers M2
Where M2.Name = M1.Name AND M1.Id>M2.Id;
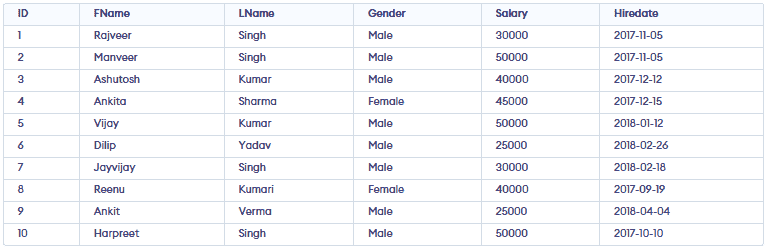
Employee Table:
👁 Screenshot-2026-02-09-115018Query:
SELECT ID, COALESCE(FName, SName, LName) as Name👁 Screenshot-2026-02-09-115436
FROM employees;
TIMESTAMPDIFF() function.Query -
Select *, TIMESTAMPDIFF (month, Hiredate, current_date()) as DiffMonth
From employees
Where TIMESTAMPDIFF (month, Hiredate, current_date())
Between 1 and 5 Order by Hiredate desc;
Output:
👁 Screenshot-2026-02-09-122141To do well in interviews, you need to understand core concepts, Database Languages, DDL, DML, DQL, Joins, etc.
1. Core Concepts:
2. Advanced Topics:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}